схема подключения к сети, с конденсатором,
Многие люди, изучая электрику, сталкиваются с такой темой как импульсное зажигающее устройство для днат. Зачем нужно ИЗУ для ДНАТ, какие технические характеристики у ИЗУ, какая схема подключения днат 250 и другие моменты представлены далее.
Для чего необходимо
Лампы ДНАТ — старые и проверенные временем светоисточники, излучающие интенсивный свет при минимальном показателе мощности. Активно используются в уличном и тепличном освещении. Из-за недостаточной цветопередачи и сильном мерцании не применяются в освещении жилых комнат.
ИЗУ для ДНАТЧтобы подключить ДНАТ, нужно использовать специальное запускающее устройство ИЗУ с пускорегулирующим аппаратом и конденсатором. Первое требуется, чтобы создать импульс высокого напряжения и образовать дугу. При этом его нужно подбирать, учитывая мощность светоисточника до 400 ватт.
Повышение напряжения ДНАТ как функция ИЗУТехнические параметры ИЗУ
Покупая импульсное зажигающее устройство, необходимо знать значение наибольшего допустимого тока, максимального частотного импульсного показателя напряжения, напряжения, функции автоматического отключения устройства и максимальной длины кабелей.
Достоинства и недостатки
Достоинства подключения импульсного зажигающего устройства к светоисточнику заключается в том, что ДНАТ функционирует на протяжении до 30 тысяч часов и качество освещения не понижается, лампа не потребляет минимум электрической энергии. Коэффициент полезного действия ламп достигает 30%.
Обратите внимание! Минусы подключения этого оборудования заключается в получающейся низкой цветовой передачи, температурном ограничении, чувствительности к электроперепадам, длительном времени включения и сильном токовой пульсации светового источника.
Простота подключения как достоинствоКак правильно подключить и проверить
Осуществить сборку комплекта для подключения светоисточника можно собственноручно. Чтобы ответить на вопрос как подключить натриевую лампу к сети, следует указать, что для этого нужна схема с лампой, балластом, импульсным зажигающим устройством и конденсатом. Обычно схема подключения находится на дроссельном корпусе для светоисточника.
Чтобы ответить на вопрос как подключить натриевую лампу к сети, следует указать, что для этого нужна схема с лампой, балластом, импульсным зажигающим устройством и конденсатом. Обычно схема подключения находится на дроссельном корпусе для светоисточника.
Схемы подключения
На схеме находится балласт с поступающей фазой, которая проводится к импульсному зажигающему устройству и потом подсоединяется к источнику. Чтобы лампочка зажглась, необходимы перечисленные выше устройства и напряжение в 220 вольт. В другом случае, запуск источника невозможен.
Схема изу подключения с конденсаторомДвухточечное ИЗУ
Зажигающие устройства, имеющие два вывода, подключаются параллельно прибору освещения. Это значит, что после дроссельной установки заряженный проводник необходимо присоединить к клемме импульсного зажигающего устройства, а другой проводник поднести к жиле, имеющей отрицательный заряд. При этом нулевой кабель можно взять от патронного элемента.
Специалисты не советуют использовать зарядники на несколько контактов, чтобы подключать световые источники, поскольку они могут навредить индуктивному балласту. Поскольку при запуске увеличивается напряжение, поступающее не только на светоисточник, но и на пускорегулирующий аппарат. Как правило, две контактные импульсные зажигающие устройства используют для нескольких ламп малой мощности до двух киловольт.
Трехточечное ИЗУ
Комплект для подсоединения ДНАТ лампочки возможно собрать в щитке с корпусом светильника. До проведения работ необходимо осуществить проверку изоляции балласта с конденсатором. Для этого осуществить переключение мультиметра на показатель максимального сопротивления. Это нужно для личной безопасности.
Для ламп, имеющих мощность в 400 ватт необходим двухфазный автоматический выключатель. Он нужен, чтобы подавать и отключать электрическое питание, защищать детали. Ставить его нужно до основных работ. Помимо этого, необходимо заземление его корпуса.
Этапы подключения импульсного зажигающего устройства с тремя выводами к натриевой лампе выглядят следующим образом:
- Проводник, имеющий отрицательный заряд из щитка подключить к светоисточнику, а второй элемент — к однотипному зажиму на зажигающем устройстве.
Обратите внимание! Ставить узел только в разрывную часть фазы, которая проходит к источнику, а не к нулю. В противном случае, будет замыкание и возгорание дросселя.
- Разомкнуть фазу и присоединить к дросселю. Жилу, которая выходит из контакта, нужно соединить к клемме В на пускорегулирующем аппарате.
- Средний проводник подключить к патрону светового источника.
Конденсаторный аппарат будет подключаться параллельно всей электроцепи. Для этого кабель нужно подвести к фазному проводнику, а второй — к нулевому.
Трехточечное ИЗУКакие бывают ошибки при подключении
При подключении может быть некорректно установлен балласт на четыре контакта. Чтобы не допустить эту ошибку, нужно пользоваться схемой подключения днат 400 с конденсатором.
Чтобы не допустить эту ошибку, нужно пользоваться схемой подключения днат 400 с конденсатором.
Могут появиться трещины на корпусе устройства в результате установки источника голыми руками. Чтобы этого избежать, следует протереть чистой салфеткой лампу до запуска.
Также может быть применен дроссель от дугового ртутного люминофорного источника при использовании балласта другого типа. Тогда лампа будет негодной для использования. Чтобы этого не происходило, нужно подбирать дроссель, отталкиваясь от типа лампы. Для этого помогут технические параметры.
В целом, ИЗУ — устройство, нацеленное на повышение напряжения до нескольких киловольт для образования дуги. Оборудование имеет двухконтактное и трехконтактное исполнение. ИЗУ вырабатывает импульсы высокого напряжения для эффективной работы натриевой лампы высокого давления.
Использование натриевых ламп и их подключение
Зачем они нужны ?По сообщению Ed Rosenthal (автор “Marijuana Grower’s Handbook”, если кто не знает) дуговые лампы (по-английски – HID) светят в два раза эффективнее, чем лампы дневного света той же мощности – это объясняется маленькими размерами излучателя, свет от которого гораздо легче направляется в нужную сторону и прочими особенностями конструкции. Поскольку ЛДС излучает по всей поверхности, сконструировать для них достаточно эффективный отражатель сложнее, размер же и расход материала будут гораздо больше. Кроме того с помощью дуговых ламп можно создать значительно большую освещенность. Потолок ее для ламп дневного света составляет 40–50 ватт на кв. фут, а с помощью HID можно без особых проблем добиться в 2–3 раза большей!Для растений (в частности, конопли) подходят две разновидности ламп класса HID – натриевые высокого давления (HPS или ДНаТ) и металл-галидные (MH, отечественный представитель – ДРИ, ртутно-иодная). С точки зрения человека натриевые лампы на 10% эффективнее металл-галидных, но с точки зрения растений – наоборот, поскольку людям и растениям нужны совершенно разные участки спектра. Вопрос этот вообще-то немного спорный, и каждый второй источник утверждает по-своему. Поскольку натриевые лампы применяются (у нас по крайней мере) гораздо шире металл-галидных, то основное внимание будет уделяться именно им. Общие рекомендации одинаково справедливы для обоих типов ламп, отличаются только электрическая часть и методы устранения неполадок.
Поскольку ЛДС излучает по всей поверхности, сконструировать для них достаточно эффективный отражатель сложнее, размер же и расход материала будут гораздо больше. Кроме того с помощью дуговых ламп можно создать значительно большую освещенность. Потолок ее для ламп дневного света составляет 40–50 ватт на кв. фут, а с помощью HID можно без особых проблем добиться в 2–3 раза большей!Для растений (в частности, конопли) подходят две разновидности ламп класса HID – натриевые высокого давления (HPS или ДНаТ) и металл-галидные (MH, отечественный представитель – ДРИ, ртутно-иодная). С точки зрения человека натриевые лампы на 10% эффективнее металл-галидных, но с точки зрения растений – наоборот, поскольку людям и растениям нужны совершенно разные участки спектра. Вопрос этот вообще-то немного спорный, и каждый второй источник утверждает по-своему. Поскольку натриевые лампы применяются (у нас по крайней мере) гораздо шире металл-галидных, то основное внимание будет уделяться именно им. Общие рекомендации одинаково справедливы для обоих типов ламп, отличаются только электрическая часть и методы устранения неполадок.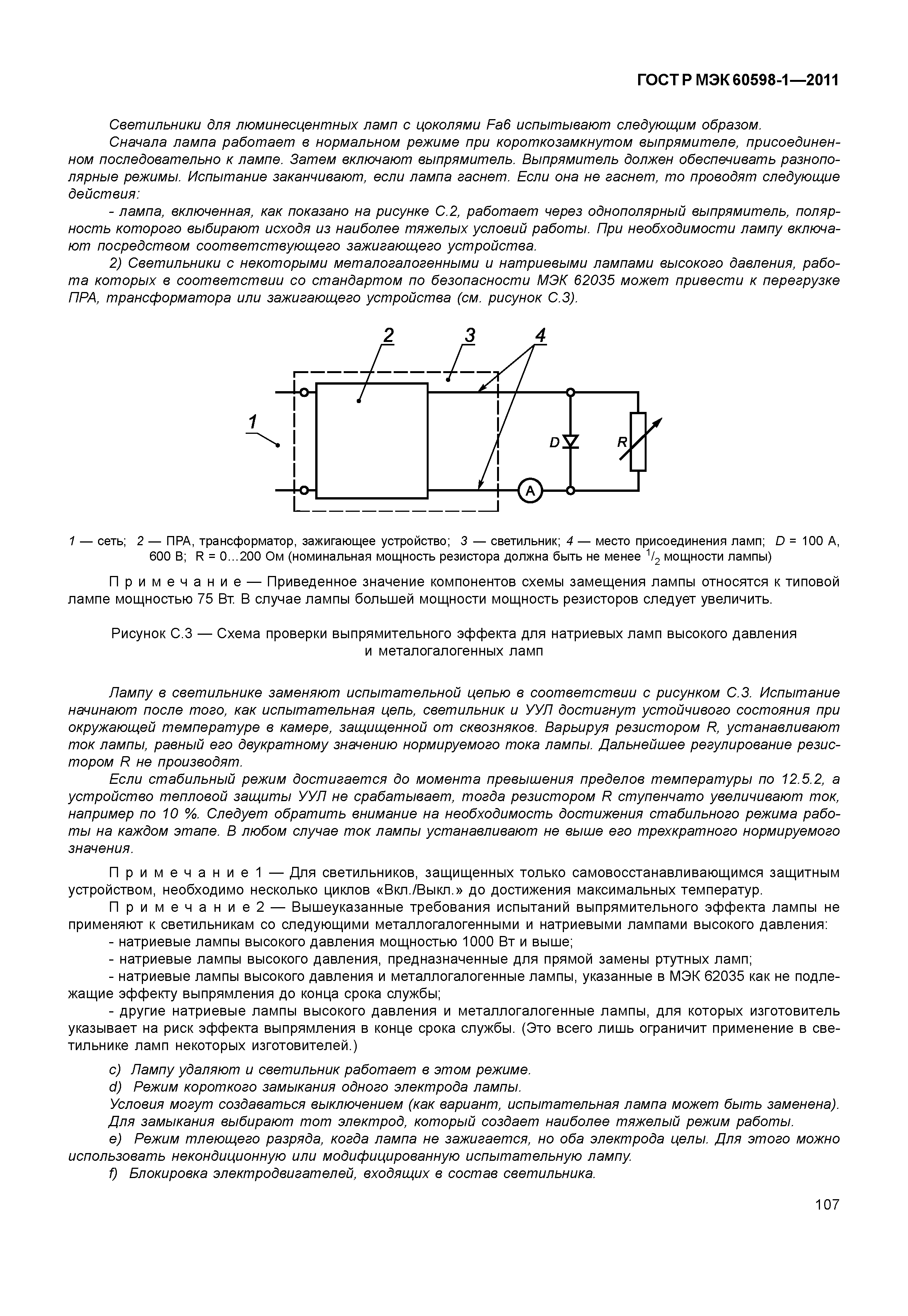
С экономической точки зрения они также гораздо выгоднее – менять лампы рекомендуется раз в полгода, а одна ДНаТ-400 успешно заменяет 15..20 ЛДС по 40 ватт. Кроме того стoит вспомнить о балластах – гораздо удобнее работать с одним среднего размера чем с пятнадцатью маленькими. Поскольку как уже говорилось электроэнергия используется дуговыми лампами вдвое эффективнее чем ЛДС, то при их использовании тот же результат получается при вдвое меньшем ее расходе. Эти лампы можно использовать даже для очень маленьких плантаций – самая маломощная ДНаТ на 70 ватт как раз подойдет для площади 1–2 кв. фута. На Рис. 3 изображена конструкция одного западного товарища, использующего метод ScrOG. Для освещения применена лампа HPS на 150 ватт, рефлектор закрыт стеклом для задержания лишних тепловых лучей. Площадь сетки с шишками – 3 кв. фута, возраст клонов – 30 (!) дней, сорт C99. Как видите, даже с далеко не идеальным рефлектором результаты просто поражают воображение!
Внутри внешнего стеклянного баллона ДНаТ’а находится «горелка» – трубка из алюминиевой керамики заполненная разреженным газом, в котором между двух электродов создается электрический разряд (дуга).
 По мере прогрева яркость растет и достигает нормального уровня через 5–10 минут.Как их устанавливать ?
По мере прогрева яркость растет и достигает нормального уровня через 5–10 минут.Как их устанавливать ?Натриевым лампам, в отличие от металл-галидных абсолютно все равно в каком положении работать. На основании многолетнего опыта западные садоводы утверждают, что горизонтальное положение лампы является более эффективным чем вертикальное, поскольку основной поток света лампа излучает в стороны. По этой же причине лампа должна располагаться посреди плантации, причем ее ось должна быть направлена поперек (перпендикулярно длинной стороне) – таким образом обеспечивается наиболее равномерная освещенность всех растений. Поскольку балласт представляет собой достаточно тяжелую железяку, его лучше вынести в отдельный блок, тогда регулировать высоту лампы будет легче. Высота подвешивания выбирается экспериментальным путем, но будьте осторожны – если вы слишком опустите лампу она может сжечь верхушки растений!
Про ИЗУ и балластыСамыми лучшими балластами для ДНаТ являются электронные, но из-за совершенно диких цен применяют их очень редко. Обычный дроссель украинского производства можно приобрести на фирме примерно за $10, если найти на базаре у алкашей – вдвое дешевле. В бывшем совке выпускается множество их модификаций и применять можно все – лишь бы дроссель был именно для ДНаТ и такой же мощности как и лампа. Ставить «родной» дроссель обязательно, в противном случае у лампы может в несколько раз сократится срок службы или катастрофически упасть светоотдача! Возможно также «мигание», когда лампа гаснет сразу же после прогрева, потом остывает и все начинается сначала…
Обычный дроссель украинского производства можно приобрести на фирме примерно за $10, если найти на базаре у алкашей – вдвое дешевле. В бывшем совке выпускается множество их модификаций и применять можно все – лишь бы дроссель был именно для ДНаТ и такой же мощности как и лампа. Ставить «родной» дроссель обязательно, в противном случае у лампы может в несколько раз сократится срок службы или катастрофически упасть светоотдача! Возможно также «мигание», когда лампа гаснет сразу же после прогрева, потом остывает и все начинается сначала…
Из отечественных ИЗУ самое удобное т.н. «УИЗУ», оно подходит для любой мощности лампы и работает со всеми балластами.
Кроме того подключение двумя проводами вместо обычных трех упрощает электрическую часть. При этом вы можете разместить УИЗУ как рядом с балластом, так и возле лампы, подключив непосредственно к ее контактам (см. схему ниже). При подключении УИЗУ полярность особой роли не играет, но рекомендуется чтобы красный («горячий») провод соединялся с балластом.
Соединения выполняются многожильным проводом достаточно большого сечения, сетевой шнур также должен быть рассчитан на большой ток. Настоятельно рекомендую ввести в эту схему предохранитель, в случае пробоя балласта он поможет предотвратить неприятные последствия – от выбивания пробок до пожара или взрыва лампы!
БЕЗОПАСНОСТЬЕсли вы собирали светильник сами – трижды убедитесь что схема абсолютна правильна! Если на вашем балласте не нарисована схема подключения, или количество ножек у балласта/ИЗУ не совпадает со схемой – проконсультируйтесь с продавцом этого барахла или опытным электриком. Последствия ошибки могут быть катастрофическими, начиная с выгорания любого из трех элементов схемы и заканчивая взрывом лампы (а стекло там толстое, да и осколки горелки с температурой больше тысячи градусов штука неприятная). Все электрические соединения выполняются толстым многожильным проводом, пайки должны быть надежными и без «соплей». Винты в соединительных колодках затягиваются плотно, но без чрезмерных усилий – чтоб не сломать колодку.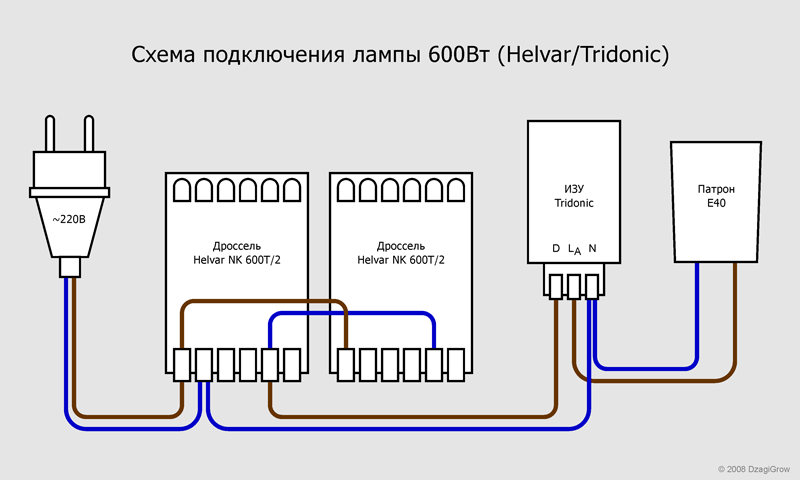 Если на баллоне лампы имеется грязь, жир или что-то подобное то из-за неравномерного нагрева лампа может лопнуть (взорваться) сразу же после прогрева! Поэтому избегайте прикасаться к лампе руками и после установки ее в патрон на всякий случай протрите спиртом. Попадание капель воды или других жидкостей на включенную лампу вызывает взрыв со 100% вероятностью! При использовании вентилятора убедитесь что он вращается и дует воздух куда надо. Подвешивайте светильник надежно, чтобы избежать падения – он тяжелый и несколько растений сломает точно, еще и загореться, сука, может!
Если на баллоне лампы имеется грязь, жир или что-то подобное то из-за неравномерного нагрева лампа может лопнуть (взорваться) сразу же после прогрева! Поэтому избегайте прикасаться к лампе руками и после установки ее в патрон на всякий случай протрите спиртом. Попадание капель воды или других жидкостей на включенную лампу вызывает взрыв со 100% вероятностью! При использовании вентилятора убедитесь что он вращается и дует воздух куда надо. Подвешивайте светильник надежно, чтобы избежать падения – он тяжелый и несколько растений сломает точно, еще и загореться, сука, может!
Несколько слов про электробезопасность… Исключите возможность попадания на балласт воды, уберите его подальше и подвесьте повыше! Провода должны иметь абсолютно целую изоляцию, лучше применить специальный провод для суровых условий. Помните, что в момент зажигания лампы ИЗУ вырабатывает импульсы очень высоко напряжения – может и не убъет но запомнится на всю жизнь Ж:0 Это кроме «обычных» 220 вольт, которые присутствуют по всей схеме. При ремонте (см. следующий раздел) некоторые измерения проводятся на включенном устройстве – ни в коем случае не делайте этого сами если у вас нет достаточного опыта работы с высоким напряжением!! Лучше раскошелится на поллитру для ближайшего электрика чем самому стать органическим удобрением
При ремонте (см. следующий раздел) некоторые измерения проводятся на включенном устройстве – ни в коем случае не делайте этого сами если у вас нет достаточного опыта работы с высоким напряжением!! Лучше раскошелится на поллитру для ближайшего электрика чем самому стать органическим удобрением
В процессе работы светильника хотя бы раз в месяц нужно стирать пыль с лампы и рефлектора и проверять состояние вентилятора. Лампы рекомендуется менять раз в 4–6 месяцев, поскольку к концу срока службы у них сильно падает светоотдача. И не опускайте лампу слишком низко, проверьте рукой температуру на уровне верхушек – сильного тепла быть не должно!
Если оно не работает ?По мере старения натриевые лампы приобретают мерзкую привычку «мигать» т.е. лампа включается, разогревается как обычно, потом вдруг гаснет и через минуту все повторяется. Если вы заметили за ней такое поведение – попробуйте поменять лампу. В случае если смена лампы не помогает – померяйте напряжение в сети, возможно оно ниже обычного. .. Если мигание происходит нерегулярно – возможно виноват плохой контакт или скачки напряжения в сети. Самая неприятная возможность – это замыкание между витками обмотки в балласте, тогда придется его менять. Иногда «мигают» и новые лампы, но у них это через несколько часов проходит.
.. Если мигание происходит нерегулярно – возможно виноват плохой контакт или скачки напряжения в сети. Самая неприятная возможность – это замыкание между витками обмотки в балласте, тогда придется его менять. Иногда «мигают» и новые лампы, но у них это через несколько часов проходит.
Бывает, что после включения светильника слышно как трещит ИЗУ (т.е. напряжение есть), но лампа даже не пытается зажечься. Чаще всего это случается из-за пробоя с проводе, идущем от ИЗУ к лампе или говорит о полностью выгоревшей лампе, реже бывает виноват обрыв провода между балластом и фонарем или подгоревшее ИЗУ. Попробуйте сменить провод между ИЗУ и лампой. Обратите внимание на состояние контактов ИЗУ. Если не поможет – попробуйте поменять лампу. Если не помогает – отключите ИЗУ (иначе своими импульсами оно может сжечь вольтметр!) и померяйте напряжение на патроне лампы – у ДНаТ оно должно соответствовать сетевому. Если напряжение на патроне есть – меняйте ИЗУ.
Если же светильник вообще не подает признаков жизни: ИЗУ не жужжит, лампа не светится – скорее всего или выбило предохранитель или нарушен контакт в сетевом шнуре. Возможно виновато сгоревшее ИЗУ или обрыв обмотки в балласте – проверьте балласт как описано ниже, если он целый – меняйте ИЗУ.
Возможно виновато сгоревшее ИЗУ или обрыв обмотки в балласте – проверьте балласт как описано ниже, если он целый – меняйте ИЗУ.
Балласт проверяется обычным Ом метром. В норме сопротивление у них порядка 1–2 Ом. Если сопротивление значительно больше – значит или обрыв в обмотке или нарушен контакт между выводами обмотки и соединительной колодкой (попробуйте подтянуть винты). При меж витковом замыкании все сложнее – на сопротивление постоянному току оно влияет очень мало из-за чего трудно обнаруживается, при этом мощность на лампу поступает гораздо большая чем надо. Когда на лампе передоз по мощности – она быстро перегревается и гаснет, в результате наблюдается все то же «мигание».
Не спешите выкидывать убитую (по вашему мнению) запчасть, может проблема и не в ней.
Использование ламп ДНАТ для растений
Лампы типа ДНАТ, светят в два раза эффективнее, чем лампы дневного света той же мощности – это объясняется маленькими размерами излучателя, свет от которого гораздо легче направляется в нужную сторону и прочими особенностями конструкции. Поскольку ЛДС излучает по всей поверхности, сконструировать для них достаточно эффективный отражатель сложнее. Научным путем был проведен расчет площади освещения подтверждающий, что с помощью ДНАТ создать значительно большую площадь освещения проще.
Поскольку ЛДС излучает по всей поверхности, сконструировать для них достаточно эффективный отражатель сложнее. Научным путем был проведен расчет площади освещения подтверждающий, что с помощью ДНАТ создать значительно большую площадь освещения проще.
ДНАТ использовать гораздо выгоднее и с экономической стороны, рекомендуется производить замену раз в полгода, а одна ДНаТ 400 ватт – заменяет 15..20 ЛДС по 40 ватт. Еще стоит отметить, что 1 большой балласт – гораздо удобнее чем с пятнадцать маленьких необходимых для ЛДС. Электроэнергия используется ДНАТ вдвое эффективнее чем ЛДС при том же результате.
Принципы работы ламп ДНАТ
Внутри внешнего стеклянного баллона ДНаТ’а находится «горелка» – трубка из алюминиевой керамики заполненная разреженным газом, в котором между двух электродов создается электрический разряд (дуга). В горелку также вводится ртуть и натрий (в ДРИ вместо натрия применяются галиды различных металлов, и горелка делается из кварцевого стекла) Для ограничения тока дуги используется специальный индуктивный (дроссель) или электронный балласт. Для зажигания холодной лампы напряжения сети недостаточно, поэтому необходимо использовать специальное импульсное зажигающее устройство – ИЗУ. Сразу же после включения оно генерирует импульсы напряжением несколько тысяч вольт, которые гарантированно пробивают лампу и создают дугу. «Натриевыми» лампы ДНаТ называют за то, что основной поток излучения генерируется ионами натрия, поэтому их свет имеет характерную желтую окраску. При работе «горелка» разогревается до 1300 °C, поэтому для сохранения ее в целости из внешнего баллона откачан воздух. Внимание: у всех без исключения дуговых ламп температура баллона при работе превышает 100 °С! Без принудительного охлаждения температура рефлектора будет ненамного меньше. Сразу после возникновения дуги лампа светит очень слабо, вся энергия расходуется на прогрев горелки. Яркость ламп стабилизируется после 5-10 минут работы.
Для зажигания холодной лампы напряжения сети недостаточно, поэтому необходимо использовать специальное импульсное зажигающее устройство – ИЗУ. Сразу же после включения оно генерирует импульсы напряжением несколько тысяч вольт, которые гарантированно пробивают лампу и создают дугу. «Натриевыми» лампы ДНаТ называют за то, что основной поток излучения генерируется ионами натрия, поэтому их свет имеет характерную желтую окраску. При работе «горелка» разогревается до 1300 °C, поэтому для сохранения ее в целости из внешнего баллона откачан воздух. Внимание: у всех без исключения дуговых ламп температура баллона при работе превышает 100 °С! Без принудительного охлаждения температура рефлектора будет ненамного меньше. Сразу после возникновения дуги лампа светит очень слабо, вся энергия расходуется на прогрев горелки. Яркость ламп стабилизируется после 5-10 минут работы.
Как правильно расположить ДНАТ?
На основании многолетнего опыта западные садоводы утверждают, что горизонтальное положение лампы является более эффективным чем вертикальное, поскольку основной поток света лампа излучает в стороны. По этой же причине лампа должна располагаться посреди оранжереи, причем ее ось должна быть направлена поперек (перпендикулярно длинной стороне) – таким образом обеспечивается наиболее равномерная освещенность всех растений.
По этой же причине лампа должна располагаться посреди оранжереи, причем ее ось должна быть направлена поперек (перпендикулярно длинной стороне) – таким образом обеспечивается наиболее равномерная освещенность всех растений.
Пока растения маленькие, нет необходимости держать их в верхней границе «оптимального диапазона», но по мере их роста необходимо максимизировать интенсивность света на более нижних участках, и будет нужно поместить их вблизи или у верхних границ «оптимального диапазона».
Учитывайте тепловое излучение лампы. Высота подвешивания выбирается экспериментальным путем, но будьте осторожны – если вы слишком опустите лампу она может сжечь верхушки растений! На более близком расстояние от лампы может потребоваться вентилятор обдувающий верхушки растений, также необходим отражатель с воздушным охлаждением лампы.
Безопасное подключение ДНАТ
Если вы собирали светильник сами – трижды убедитесь что схема подключения ДНАТ абсолютна правильна! Последствия ошибки могут быть катастрофическими, начиная с выгорания любого из трех элементов схемы и заканчивая взрывом лампы.
Все электрические соединения выполняются толстым проводом, пайки и клеммы должны быть надежными. Винты в соединительных колодках затягиваются плотно, но чтоб не сломать колодку.
Для надёжного подключения, избежания плохого контакта, предотвращения пожара и повышения безопасности:
– надо использовать медные провода и кабели
– многожильные проводники надо опрессовывать специальными наконечниками или залудить паяльником, иначе винты в клеммах перережут большую часть жил, что может вызвать перегрев контакта, оплавление, замыкание с соседними контактами и возгорание
– одножильные проводники не надо опрессовывать наконечниками, в этом случае наконечник не нужный, а значит – лишний элемент, который уменьшает надёжность контакта
– медь не должна торчать из клемм, зачищенная часть провода должна полностью заходить в изоляцию клеммы, иначе появляется вероятность короткого замыкания или поражения током.
Если на лампе имеется грязь, жир или отпечатки то из-за неравномерного нагрева лампа может взорваться сразу же после прогрева! Поэтому избегайте прикасаться к лампе руками и после установки ее в патрон на всякий случай протрите спиртом. Попадание капель воды или других жидкостей на включенную лампу вызывает взрыв со 100% вероятностью! При использовании вентилятора убедитесь что он вращается и дует поток воздух куда нужно.
Попадание капель воды или других жидкостей на включенную лампу вызывает взрыв со 100% вероятностью! При использовании вентилятора убедитесь что он вращается и дует поток воздух куда нужно.
Необходимо полностью исключите возможность попадания на балласт или дроссель – воды, уберите его подальше или подвесьте как можно выше. Провода должны иметь целую изоляцию. В момент зажигания лампы ИЗУ вырабатывает импульсы очень высоко напряжения – будьте предельно внимательны во избежание поражения током.
В процессе работы светильника хотя бы раз в месяц нужно стирать пыль с лампы и рефлектора и проверять загрязненность вентилятора. Лампы рекомендуется менять раз в 4–6 месяцев, поскольку к концу срока службы у них сильно падает светоотдача. Опускайте лампу слишком низко не рекомендуется, проверьте рукой температуру на уровне макушек растений – сильного обжигать не должно!
Если лампа не работает ?
По мере старения натриевые лампы приобретают мерзкую привычку «мигать» т. е. лампа включается, разогревается как обычно, потом вдруг гаснет и через минуту все повторяется. Если вы заметили за ней такое поведение – попробуйте поменять лампу. В случае если смена лампы не помогает – нежно измерить напряжение в сети, оно может быть ниже обычного… Если мигание происходит нерегулярно – возможно виноват плохой контакт или скачки напряжения в сети. Самая неприятная возможность – это замыкание между витками обмотки в балласте, тогда придется его менять. Иногда «мигают» и новые лампы, но у них это через несколько часов проходит.
е. лампа включается, разогревается как обычно, потом вдруг гаснет и через минуту все повторяется. Если вы заметили за ней такое поведение – попробуйте поменять лампу. В случае если смена лампы не помогает – нежно измерить напряжение в сети, оно может быть ниже обычного… Если мигание происходит нерегулярно – возможно виноват плохой контакт или скачки напряжения в сети. Самая неприятная возможность – это замыкание между витками обмотки в балласте, тогда придется его менять. Иногда «мигают» и новые лампы, но у них это через несколько часов проходит.
Бывает, что после включения светильника слышно как трещит ИЗУ (т.е. напряжение есть), но лампа даже не пытается зажечься. Чаще всего это случается из-за пробоя с проводе, идущем от ИЗУ к лампе или говорит о полностью выгоревшей лампе, реже бывает виноват обрыв провода между балластом и фонарем или подгоревшее ИЗУ. Попробуйте сменить провод между ИЗУ и лампой. Обратите внимание на состояние контактов ИЗУ. Если не поможет – попробуйте поменять лампу. Если не помогает – отключите ИЗУ (иначе своими импульсами оно может сжечь вольтметр!) и померяйте напряжение на патроне лампы – у ДНаТ оно должно соответствовать сетевому. Если напряжение на патроне есть – меняйте ИЗУ.
Если не помогает – отключите ИЗУ (иначе своими импульсами оно может сжечь вольтметр!) и померяйте напряжение на патроне лампы – у ДНаТ оно должно соответствовать сетевому. Если напряжение на патроне есть – меняйте ИЗУ.
Если же светильник вообще не подает признаков жизни: ИЗУ не жужжит, лампа не светится – скорее всего или выбило предохранитель или нарушен контакт в сетевом шнуре. Возможно виновато сгоревшее ИЗУ или обрыв обмотки в балласте – проверьте балласт как описано ниже, если он целый – меняйте ИЗУ.
Балласт проверяется обычным Ом метром. В норме сопротивление у них порядка 1–2 Ом. Если сопротивление значительно больше – значит или обрыв в обмотке или нарушен контакт между выводами обмотки и соединительной колодкой (попробуйте подтянуть винты). При межвитковом замыкании все сложнее – на сопротивление постоянному току оно влияет очень мало из-за чего трудно обнаруживается, при этом мощность на лампу поступает гораздо большая чем надо. Когда на лампе превышение по мощности – она быстро перегревается и гаснет, в результате наблюдается все то же «мигание».
Светильники для теплиц: как рассчитать уровень освещенности
Свет имеет первостепенное значение для растений. И особенно актуальна эта проблема при культивировании их в условиях закрытых помещений, методом гидропоники.
Свет имеет двойственную природу. С одной стороны, без него растения не могут развиваться, с другой — слишком большая температура от источников вызывает угнетение развития. Необходимо выяснить несколько взаимосвязанных вопросов: какие лампы использовать и сколько.
Для чего нужны светильники
Практика показывает, что существует прямая зависимость между количеством света и урожайностью. При плохом освещении растения оказываются недостаточно крепкими, могут неправильно развиваться и так далее. И в настоящее время примерно половина стоимости продукции теплиц — это стоимость осветительного оборудования и электричества.
Свет активирует процесс фотосинтеза, то есть, производства органических соединений из воды и окиси углерода. Важным при этом является не только интенсивность процесса, но и спектральный состав излучения. Во время роста, развития и созревания плодов преимущественно используются разные спектры.
Важным при этом является не только интенсивность процесса, но и спектральный состав излучения. Во время роста, развития и созревания плодов преимущественно используются разные спектры.
Нужно также соблюдать чередование дня и ночи. Для каждого растения длина светового дня может быть разной, что необходимо учитывать при планировании.
Пример расчета
При расчете освещенности теплицы необходимо учитывать многие параметры: тип лампы, расстояние до растений, наличие отражателей, другие оптические характеристики.
Для приблизительного расчета рекомендуется применить упрощенную формулу: F=ExS/Kи. В этом уравнении F — требуемый световой поток, S — площадь, а Ки — коэффициент использования потока. Для систем со встроенным отражателем коэффициент принимается равным 0,8, с внешним — 0,4.
Предположим, что требуется уровень в 10 000 люкс на площади 2 кв. метра. Используя лампы с внешним отражателем (Ки=0,4) получаем F=10000×2 кв. м/0,4=50 000 лм. Такой поток может обеспечить лампа ДНАТ мощностью 400 Вт (48 000 лм) или два таких источника по 250 Вт (27 000 лм каждый). Если использовать модель с зеркальным отражателем, получим требуемый поток F=25 000 лм. В результате достаточно одной лампы в 250 Вт (27 000 лм).
м/0,4=50 000 лм. Такой поток может обеспечить лампа ДНАТ мощностью 400 Вт (48 000 лм) или два таких источника по 250 Вт (27 000 лм каждый). Если использовать модель с зеркальным отражателем, получим требуемый поток F=25 000 лм. В результате достаточно одной лампы в 250 Вт (27 000 лм).
Теперь нужно экспериментально подобрать высоту подвеса. Пятно освещенности должно совпадать по площади с расчетным. Но нельзя забывать, что уровень яркости обратно пропорционален квадрату расстояния. Так как учесть все параметры в предварительном расчете невозможно, после установки источника следует проверить данные экспериментально (люксометром).
Какие лампы в каком случае можно использовать
Чтобы подсветить одно растение, можно применить лампу мощностью 20-30 Вт, подвешенную на высоте от 5 до 30 см.
Группы растений подсвечиваются лампами мощностью от 50 Вт (с расстояния 40-60 см) или мощностью в 15-100 Вт, с расстояния 50-100 см — в зависимости от размера группы.
Мощные лампы от 250 Вт лучше размещать на высоте 1-2 м в больших помещениях. А источники от 400 Вт и выше применяются для освещения зимних садов или оранжерей, для комнаты они будут слишком яркими. Кроме того, при использовании ламп большой мощности необходимо сделать расчет проводки, чтобы не допустить перегрузки системы.
Нужно также заметить, что использовать много ламп вместо одной нецелесообразно. Особенно старых ламп накаливания большого диаметра. Они начнут перегреваться и быстро выйдут из строя. Также возрастут расходы на электричество. Лучше использовать источники с рефлектором или установить отражающее покрытие стен.
При использовании гроубоксов или гроутентов не стоит выбирать лампы большой мощности, натриевые или лампы накаливания, так как они слишком сильно греются. А внутренняя отделка отражающим покрытием делает освещенность намного ярче. Но в каждом случае необходимо использовать люксометр.
Балансировка нагрузки— виртуальный сервер Linux (LVS) и его режимы пересылки
В этой статье показано, как разные режимы Linux Virtual Server (LVS) реализуют балансировку нагрузки, и описаны преимущества и недостатки каждого принципа пересылки сетевых пакетов.
Автор Ren Xijun (Чжэцзянь).
В этой статье объясняются режимы пересылки виртуального сервера Linux (LVS) и их рабочие процессы.В нем описаны причины, преимущества и недостатки принципа пересылки сетевых пакетов, а также показаны достоинства и недостатки с учетом балансировщика нагрузки (SLB) Alibaba Cloud Server.
Термины, сокращения и акронимы
Давайте кратко рассмотрим различные термины и сокращения, используемые в статье.
cip : Клиентский IP , 客户 端 地址
vip : Виртуальный IP , LVS 实例 IP
рип : Настоящий IP , 后端 RS 地址
RS: Настоящий сервер 真正 提供 服务 的 机器
LB : Балансировка нагрузки 负载 均衡 器
LVS : Виртуальный сервер Linux
sip : исходный ip
падение : место назначения
Режимы пересылки LVS
Виртуальный сервер Linux помогает балансировать нагрузку, устраняя единую точку отказа (SPOF).Есть несколько способов пересылки пакетов;
- DR — Директор по маршрутизации
- NAT — преобразование сетевых адресов
- fullNAT — Полный NAT
- ENAT — Расширенный NAT, также известный как режим треугольника или DNAT, определяется Alibaba Cloud
- IP TUN — IP-туннелирование
Директор маршрутизации (DR)
На предыдущей диаграмме показано, как работает режим DR LVS. Теперь давайте рассмотрим следующий пример, чтобы понять процесс.
Теперь давайте рассмотрим следующий пример, чтобы понять процесс.
Предположим, что CIP — 200.200.200.2, а VIP — 200.200.200.1.
- Шаг 1 Трафик запроса с IP-адресом источника (SIP) 200.200.200.2 и IP-адресом назначения (DIP) 200.200.200.1 (с псевдонимом (200.200.200.2, 200.200.200.1)) сначала достигает LVS.
- Шаг 2 Затем LVS выбирает один из RS в соответствии с политикой загрузки и меняет MAC-адрес этого сетевого пакета на MAC-адрес выбранного RS.
- Шаг 3 Наконец, LVS передает этот сетевой пакет коммутатору, который затем передает сетевой пакет выбранному RS.
- Шаг 4 Когда выбранный RS обнаруживает, что и MAC-адрес, и DIP принадлежат ему, он напрямую управляет сетевым пакетом и отвечает на него.
- Шаг 5 Выбранный RS отвечает пакетом (200.200.200.1, 200.200.200.2).
- Шаг 6 Коммутатор напрямую пересылает ответный пакет клиенту, минуя LVS.


Как показано в предыдущем процессе, после того, как пакет запроса прибывает в LVS, он просто изменяет MAC-адрес назначения пакета и пересылает ответный пакет непосредственно клиенту.
Кроме того, обратите внимание, что несколько RS и LVS имеют один и тот же IP-адрес, но используют разные MAC-адреса. Маршруты L2 не требуют IP-адресов, поэтому RS и LVS находятся в одной VLAN.
RS настраивает VIP на контроллере сетевого интерфейса (NIC) с обратной связью LO и добавляет соответствующее правило к маршруту, чтобы операционная система (ОС) обрабатывала пакеты, полученные на шаге 4.
Преимущества
- Режим DR обеспечивает наилучшую производительность.Входящий запрос проходит через LVS, а пакет ответа напрямую отправляется клиенту, минуя LVS.
Недостатки
- LVS и RS должны принадлежать одной VLAN.
- Этот режим требует настройки между RS и VIP и, в частности, обработки протокола разрешения адресов (ARP).
- Не поддерживает отображение портов.

Почему LVS и RS должны принадлежать одной VLAN или одной сети L2?
В режиме DR несколько RS и LVS совместно используют один и тот же VIP, и пакеты маршрутизируются между LVS и RS на основе MAC-адреса.Следовательно, LVS и RS должны принадлежать одной и той же сети VLAN или L2.
Причина лучшей производительности в режиме DR
Ответные пакеты не проходят через LVS. В большинстве случаев пакеты запросов небольшие, а пакеты ответов большие, что легко приводит к узкому месту трафика на LVS. Кроме того, в режиме DR LVS изменяет только MAC-адреса входящих пакетов.
Почему пакеты обходят LVS в режиме DR
RS и LVS используют один и тот же VIP. Следовательно, RS правильно устанавливает свой SIP для VIP, отвечая на пакет, без необходимости изменения SIP для LVS.Напротив, LVS изменяет SIP в режимах NAT и full NAT.
Сводка структурыв режиме DR
На приведенной выше диаграмме показана общая структура в режиме DR. Зеленая стрелка указывает пакет входящего запроса, а красная стрелка указывает пакет запроса с измененным MAC-адресом.
Зеленая стрелка указывает пакет входящего запроса, а красная стрелка указывает пакет запроса с измененным MAC-адресом.
Преобразование сетевых адресов (NAT)
На следующем рисунке показана структура в режиме NAT.
Общий процесс для этого режима следующий.
- Шаг 1 Клиент отправляет пакет запроса (200.200.200.2, 200.200.200.1).
- Шаг 2 Когда пакет запроса прибывает в LVS, LVS изменяет пакет запроса на (200.200.200.2, RIP).
- Шаг 3 Далее, когда пакет запроса прибывает в RS, он отвечает пакетом ответа (RIP, 200.200.200.2).
- Шаг 4 Важно отметить, что этот ответный пакет нельзя напрямую отправить клиенту, поскольку RIP не является VIP и его необходимо сбросить.
- Шаг 5 Однако LVS — это шлюз. Следовательно, этот ответный пакет сначала отправляется на шлюз, который затем меняет SIP.
- Шаг 6 Шлюз изменяет SIP на VIP и отправляет клиенту измененный пакет ответа (200. 200.200.1, 200.200.200.2).
 200.200.1, 200.200.200.2).
200.200.1, 200.200.200.2).Преимущества
- Конфигурация простая.
- Как следует из названия, NAT поддерживает отображение портов.
- RIP — это частный адрес, который в основном обеспечивает связь между LVS и RS.
Недостатки
- LVS и все RS должны принадлежать одной VLAN.
- LVS должен пересылать весь входящий и исходящий трафик.
- LVS часто становится узким местом.
- Установите VIP на IP-адрес шлюза для RS.
Почему LVS и RS принадлежат одной и той же VLAN в режиме NAT?
Клиент распознает ответный пакет только после того, как LVS изменит SIP на VIP. Если SIP ответного пакета не является DIP (или VIP) пакета запроса, отправленного клиентом, соединение сбрасывается.Во-вторых, если LVS не является шлюзом, ответный пакет пересылается по другим маршрутам, потому что DIP ответного пакета — это CIP. В этом случае LVS не может изменить SIP ответного пакета.
в режиме NAT
Поскольку LVS изменяет только SIP или DIP входящих и исходящих пакетов, полный режим NAT появляется как дополнение. Самым большим недостатком режима NAT является то, что LVS и RS должны принадлежать одной и той же VLAN, что ограничивает гибкость развертывания LVS-кластера и RS-кластера.NAT в основном непрактичен в коммерческих общедоступных облачных средах, таких как Alibaba Cloud.
Полный NAT
Этот режим аналогичен режиму NAT. Общий процесс для этого режима следующий.
- Шаг 1 Клиент отправляет пакет запроса (200.200.200.2, 200.200.200.1).
- Шаг 2 Когда пакет запроса достигает LVS, LVS изменяет пакет запроса на (200.200.200.1, RIP). Обратите внимание, что здесь меняются как SIP, так и DIP.
- Шаг 3 Когда пакет запроса прибывает в RS, RS отвечает пакетом (RIP, 200.200.200.1).
- Шаг 4 В отличие от режима NAT, в котором вы устанавливаете DIP на CIP, здесь DIP этого пакета ответа является VIP. Следовательно, когда LVS и RS не принадлежат к одной и той же VLAN, ответный пакет по-прежнему достигает LVS через IP-маршруты.
- Шаг 5 LVS изменяет SIP на VIP и DIP на CIP соответственно и отправляет измененный пакет ответа (200.200.200.1, 200.200.200.2) клиенту.
 Следовательно, когда LVS и RS не принадлежат к одной и той же VLAN, ответный пакет по-прежнему достигает LVS через IP-маршруты.
Следовательно, когда LVS и RS не принадлежат к одной и той же VLAN, ответный пакет по-прежнему достигает LVS через IP-маршруты.Преимущества
- Этот режим решает проблему режима NAT и не требует, чтобы LVS и RS принадлежали одной и той же VLAN. Следовательно, он применим к более сложным сценариям развертывания.
Недостатки
- В отличие от режима NAT, CIP невидим для RS. Подобно режиму NAT, весь входящий и исходящий трафик по-прежнему проходит через LVS, что является узким местом.
Как полный NAT решает проблему LVS и RS в режиме NAT?
Исходя из названия, Full NAT LVS изменяет и SIP, и DIP входящего пакета.Кроме того, DIP ответного пакета от RS — это VIP (который является CIP в режиме NAT). Следовательно, LVS и RS могут принадлежать разным VLAN при условии, что сеть L3 между VIP и RS доступна. Другими словами, LVS больше не должен быть шлюзом, и LVS и RS могут быть развернуты в более сложной сетевой среде.
Другими словами, LVS больше не должен быть шлюзом, и LVS и RS могут быть развернуты в более сложной сетевой среде.
Почему протокол CIP невидим для RS в режиме полного NAT?
Поскольку CIP изменяется в режиме Full NAT, RS может видеть только VIP LVS. В Alibaba поле Option TCP-пакета содержит CIP.При получении пакета RS обычно развертывает самоопределяемый модуль TOA для чтения CIP от Option. В этом случае RS может видеть CIP. Однако это не универсальное решение с открытым исходным кодом.
Сводная информация о структуре в режиме полного NAT
Важно отметить изменения IP-адресов для зеленого входящего пакета и красного исходящего пакета на предыдущем рисунке.
Пока что полный NAT отвечает тем же требованиям к VLAN, что и в режиме NAT, и в основном готов для общедоступного облака. Однако это все еще не решает проблему, заключающуюся в том, что весь входящий и исходящий трафик проходит через LVS, что означает, что LVS необходимо изменить входящие и исходящие пакеты.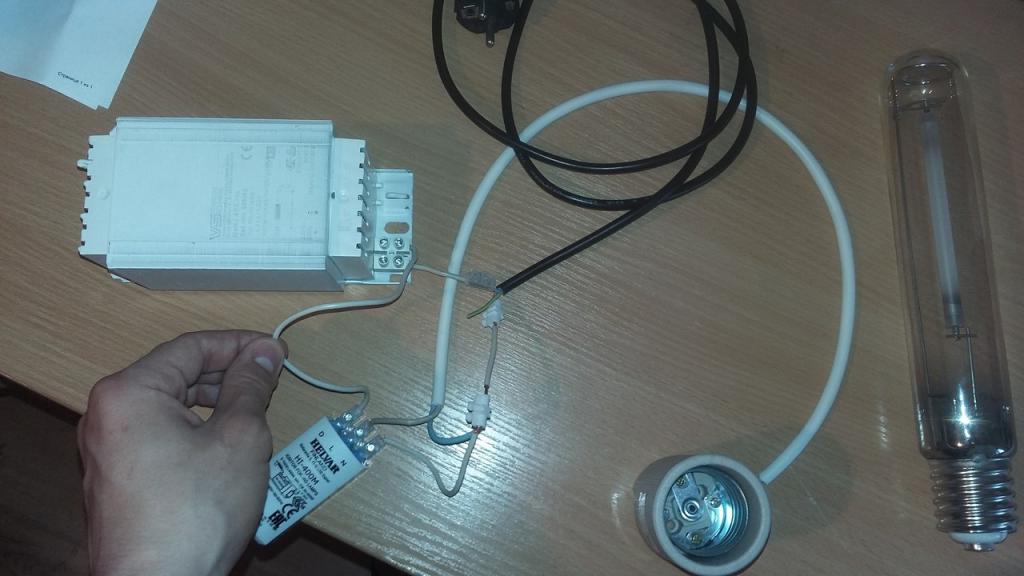
Задача здесь состоит в том, чтобы определить, существует ли решение, которое не ограничивает сетевые отношения между LVS и RS, превалирующими в режиме полного NAT, и позволяет исходящему трафику обходить LVS, как в режиме DR.
Режим расширенного NAT (ENAT) в Alibaba Cloud
Режим расширенного NAT (ENAT) также известен как режим треугольника или режим DNAT.Общий процесс для этого режима следующий:
- Шаг 1 Клиент отправляет пакет запроса (CIP, VIP).
- Шаг 2 При получении пакета запроса LVS изменяет пакет запроса на (VIP, RIP) и добавляет CIP в поле Option пакета TCP.
- Шаг 3 На основе IP-адреса пакет запроса направляется к RS, и модуль CTK считывает CIP из поля Option пакета TCP.
- Шаг 4 Модуль CTK перехватывает ответный пакет (RIP, VIP) и изменяет его на (VIP, CIP).
- Шаг 5 Ответный пакет не проходит через LVS и не отправляется напрямую клиенту, потому что DIP ответного пакета — это CIP.

Преимущества
- LVS и RS могут принадлежать разным VLAN.
- Исходящий трафик обходит LVS, что обеспечивает хорошую производительность.
Недостатки
- Специальное решение Alibaba Group требует, чтобы все RS установили компонент CTK (аналогично модулю TOA в режиме полного NAT).
Почему режим ENAT не требует маршрутизации пакетов обратного ответа на LVS?
В режиме полного NAT LVS должен изменить IP-адрес в ответном пакете, и поэтому ответный пакет должен маршрутизироваться обратно в LVS. Однако в режиме ENAT модуль CTK на RS заранее изменяет IP в ответном пакете.
Почему LVS и RS могут принадлежать разным VLAN в режиме ENAT?
Причина та же, что обсуждалась ранее для режима полного NAT.
Краткое описание структуры в режиме ENAT
IP-туннелирование (IP TUN)
Наконец, давайте взглянем на менее используемый режим IP TUN. Общий процесс для этого режима следующий:
Общий процесс для этого режима следующий:
- Шаг 1 Когда пакет запроса прибывает в LVS, он инкапсулирует пакет запроса в новый IP-пакет.
- Шаг 2 LVS устанавливает DIP нового IP-пакета на IP-адрес RS, а затем пересылает IP-пакет на RS.
- Шаг 3 После того, как RS получает пакет, модуль ядра IPIP декапсулирует его и извлекает сообщение запроса пользователя.
- Шаг 4 Обнаружив, что DIP является VIP и этот IP-адрес настроен для NIC tun10 RS, RS напрямую обрабатывает запрос и отправляет результаты клиенту.
Преимущества
- Узлы кластера могут принадлежать разным VLAN.
- Подобно режиму DR, клиент напрямую получает ответные пакеты.
Недостатки
- Этот режим требует RS для установки модуля IPIP.
- Добавляет еще один заголовок IP.
- Подобно режиму DR, виртуальные сетевые адаптеры tunl0 LVS и RS должны устанавливать один и тот же VIP.

Примечание: В режиме DR LVS изменяет MAC-адрес назначения.
Почему узлы кластера принадлежат к разным VLAN в режиме IP TUN?
MAC-адрес остается неизменным в режиме IP TUN. Следовательно, узлы кластера могут принадлежать к разным VLAN, при условии, что связь между IP-адресами LVS и RS доступна. Трансляции между LVS и RS должны быть доступны в режиме DR.
IP TUN Performance
Ответный пакет обходит LVS. Однако по сравнению с обработкой в режиме DR этот режим допускает дополнительную инкапсуляцию и декапсуляцию пакета ответа.
Обзор структуры в режиме IP TUN
На предыдущем рисунке красная линия указывает повторно инкапсулированный пакет, тогда как модуль IPIP указывает модуль ядра ОС.
Заключение
Эта статья проливает свет на различные режимы виртуального сервера Linux (LVS). Он охватывает довольно популярный режим DR вместе с менее известным режимом IP TUN. Кроме того, он также выделяет другие три режима, которые являются аналогичными и более популярными. Надеюсь, вы сочтете рабочий процесс каждого режима LVS, описанный в этой статье, практичным.
Надеюсь, вы сочтете рабочий процесс каждого режима LVS, описанный в этой статье, практичным.
OpenStack Floating IP — публичные и частные облачные сети
Mirantis OpenStack Express Версия для разработчиков: Получите частное облако как услугу на год бесплатно . Недавно я рассказал, как работает VlanManager и как он обеспечивает масштабируемость сети и изоляцию клиентов. Однако до этого момента я имел дело только с фиксированными IP-сетями разных арендаторов. Хотя фиксированные IP-адреса — это то, что экземпляры предоставляются по умолчанию, они не гарантируют немедленную доступность экземпляра из внешнего мира (или из остальной части центра обработки данных).Представьте себе следующий сценарий: Вы запускаете небольшой веб-сайт LAMP с одним www-сервером, сервером базы данных и брандмауэром, который обрабатывает трансляцию сетевых адресов (NAT) и фильтрацию трафика. Обычно вы хотите, чтобы применялись следующие условия:- Все серверы внутренне обмениваются данными в некотором частном (не маршрутизируемом) диапазоне сети (например, 192. 168.0.0/24).
- Существует один общедоступный маршрутизируемый IP-адрес, на котором виден www-сервер.
 168.0.0/24).
168.0.0/24).- Настройте брандмауэр с общедоступным IP-адресом.
- Создайте правило NAT на брандмауэре для перенаправления трафика с общедоступного IP-адреса на частный IP-адрес сервера www.
Разница между фиксированным и плавающим IP-адресом
По умолчанию плавающие IP-адреса не назначаются экземплярам. Пользователи облака должны явно «захватить» их из существующего пула, настроенного администратором OpenStack, а затем присоединить их к своим экземплярам. Как только пользователь получил плавающий IP-адрес из пула, он становится его «владельцем» (т.е. в любой момент он может отсоединить IP от данного экземпляра и присоединить его к другому).Если по какой-то причине экземпляр умирает, пользователь не теряет плавающий IP-адрес — он остается его собственным ресурсом, готовым к подключению к другому экземпляру. С другой стороны, фиксированные IP-адреса выделяются динамически компонентом nova-network при загрузке экземпляров. Невозможно указать OpenStack назначить конкретный фиксированный IP-адрес экземпляру. Таким образом, вы, вероятно, окажетесь в ситуации, когда после того, как вы случайно завершите работу виртуальной машины и восстановите ее из моментального снимка, новый экземпляр, скорее всего, загрузится с другим фиксированным IP-адресом.Системные администраторы могут настроить несколько пулов плавающих IP-адресов.
Пользователи облака должны явно «захватить» их из существующего пула, настроенного администратором OpenStack, а затем присоединить их к своим экземплярам. Как только пользователь получил плавающий IP-адрес из пула, он становится его «владельцем» (т.е. в любой момент он может отсоединить IP от данного экземпляра и присоединить его к другому).Если по какой-то причине экземпляр умирает, пользователь не теряет плавающий IP-адрес — он остается его собственным ресурсом, готовым к подключению к другому экземпляру. С другой стороны, фиксированные IP-адреса выделяются динамически компонентом nova-network при загрузке экземпляров. Невозможно указать OpenStack назначить конкретный фиксированный IP-адрес экземпляру. Таким образом, вы, вероятно, окажетесь в ситуации, когда после того, как вы случайно завершите работу виртуальной машины и восстановите ее из моментального снимка, новый экземпляр, скорее всего, загрузится с другим фиксированным IP-адресом.Системные администраторы могут настроить несколько пулов плавающих IP-адресов. Однако, в отличие от пулов с фиксированными IP-адресами, пулы с плавающими IP-адресами не могут быть сопоставлены определенным клиентам. Каждый пользователь может «получить» плавающий IP-адрес из любого пула плавающих IP-адресов. Но основная мотивация нескольких пулов плавающих IP-адресов заключается в том, что каждый из них может обслуживаться разными интернет-провайдерами. Таким образом, мы можем гарантировать, что мы поддерживаем высокую доступность и возможность подключения, даже если один из интернет-провайдеров столкнется с поломкой. Подводя итог, можно сказать, что ключевыми особенностями плавающих IP-адресов являются:
Однако, в отличие от пулов с фиксированными IP-адресами, пулы с плавающими IP-адресами не могут быть сопоставлены определенным клиентам. Каждый пользователь может «получить» плавающий IP-адрес из любого пула плавающих IP-адресов. Но основная мотивация нескольких пулов плавающих IP-адресов заключается в том, что каждый из них может обслуживаться разными интернет-провайдерами. Таким образом, мы можем гарантировать, что мы поддерживаем высокую доступность и возможность подключения, даже если один из интернет-провайдеров столкнется с поломкой. Подводя итог, можно сказать, что ключевыми особенностями плавающих IP-адресов являются:- Плавающие IP-адреса не назначаются экземплярам автоматически по умолчанию (их нужно присоединять к экземплярам вручную).
- Если экземпляр умирает, пользователь может повторно использовать плавающий IP-адрес, подключив его к другому экземпляру.
- Пользователи могут захватывать плавающие IP-адреса из разных пулов, определенных администратором облака, чтобы обеспечить подключение к экземплярам от разных интернет-провайдеров или внешних сетей.

Плавающие IP-адреса — внутренние и публичные облака
«Общедоступность» плавающих IP-адресов — понятие относительное. Для общедоступных облаков вы, вероятно, захотите определить пул плавающих IP-адресов как пул IP-адресов, общедоступных из Интернета.Затем ваши клиенты назначают их экземплярам для входа в них через SSH со своих домашних / офисных компьютеров: Если вы запускаете корпоративное облако в своем центре обработки данных, тогда пул плавающих IP-адресов может быть любым диапазоном IP-адресов, который предоставляет экземпляры OpenStack для остальной части вашего центра обработки данных. Для трафика вашего центра обработки данных вам может быть определен следующий диапазон: 10.0.0.0/16. Внутри OpenStack у вас может быть следующий фиксированный диапазон IP-адресов: 192.168.0.0/16, разделенный на подсети клиентов. Чтобы сделать экземпляры OpenStack доступными из остальной части вашего центра обработки данных, вы можете определить пул плавающих IP-адресов как подсеть из 10. 0.0.0 / 8 (т.е. 10.0.0.0/16) и зарегистрируйте его в OpenStack, чтобы пользователи могли получить его.
0.0.0 / 8 (т.е. 10.0.0.0/16) и зарегистрируйте его в OpenStack, чтобы пользователи могли получить его.Работа с плавающими IP-адресами
Как я упоминал ранее, сначала системный администратор регистрирует плавающий пул IP-адресов в OpenStack:nova-manage Floating create --ip_range = PUBLICLY_ROUTABLE_IP_RANGE --pool POOL_NAMEТаким образом, общественный бассейн становится доступным для арендаторов. Теперь пользователи следят за этим рабочим процессом:
- Загрузите экземпляр:
+ -------------------------------------- + --------- + -------- + -------------------------------- + | ID | Имя | Статус | Сети | + -------------------------------------- + --------- + -------- + -------------------------------- + | 79935433-241a-4268-8aea-5570d74fcf42 | inst1 | АКТИВНЫЙ | частный = 10.0.0.4 | + -------------------------------------- + --------- + -------- + -------------------------------- +
- Список доступных пулов плавающих IP:
nova список плавающих IP-адресов + ------ + | имя | + ------ + | паб | | тест | + ------ +
- Возьмите плавающий IP-адрес из пула «pub» (или «test», если хотите):
nova Floating-ip-create pub + --------------- + ------------- + ---------- + ------ + | Ip | Идентификатор экземпляра | Фиксированный IP | Бассейн | + --------------- + ------------- + ---------- + ------ + | 172.24.4.225 | Нет | Нет | паб | + --------------- + ------------- + ---------- + ------ +
- Назначьте плавающий IP-адрес экземпляру:
nova add-float-ip 79935433-241a-4268-8aea-5570d74fcf42 172.24.4.225
(где первый аргумент — это uuid экземпляра, а второй — сам плавающий IP-адрес) - Проверьте обратную связь, чтобы убедиться, что все настроено правильно:
nova плавающий IP-список + -------------- + ---------------------------------- ---- + ---------- + ------ + | Ip | Идентификатор экземпляра | Фиксированный IP | Бассейн | + -------------- + ---------------------------------- ---- + ---------- + ------ + | 172.24.4.225 | 79935433-241a-4268-8aea-5570d74fcf42 | 10.0.0.4 | паб | + -------------- + ---------------------------------- ---- + ---------- + ------ +
Как работают плавающие IP-адреса
Итак, что происходит внутри экземпляра после добавления плавающего IP? Ответ… ничего. Если вы войдете в систему через SSH и отобразите конфигурацию сети, вы увидите, что все еще существует один сетевой интерфейс с настроенным фиксированным IP.Вся настройка выполняется на самом вычислительном узле. Вся работа с плавающим IP — это работа nova-network, что означает настройку NAT между фиксированным и плавающим IP-адресами экземпляра. Объяснение того, как работает NAT, можно найти здесь. Взгляните на следующую диаграмму: На нем показан один вычислительный узел, настроенный в режиме многоузловой сети, и VlanManager, используемый для настройки фиксированных IP-сетей. Вычислительный узел оснащен двумя сетевыми интерфейсами: eth0 предназначен для фиксированного трафика IP / VLAN, а eth2 — это интерфейс, на котором вычислительный узел подключен к внешнему миру и к которому идут плавающие IP-адреса.(Чтобы узнать, как VlanManager настраивает фиксированные IP-сети, см. Предыдущий пост.) Обратите внимание, что хотя на интерфейсе eth0 (фиксированный / частный) адрес не настроен, для интерфейса eth2 назначен IP-адрес, который также является шлюзом по умолчанию для вычислительного узла (91.207.15.105). Когда пользователь назначает плавающий IP-адрес (91.207.16.144) экземпляру VM_1, происходят две вещи:- Плавающий IP-адрес настроен как вторичный адрес на eth2: Это результат «
ip addr show eth2», содержащий соответствующие записи:инет 91.207.15.105 / 24 область действия global eth2 # primary eth2 ip inet 91.207.16.144/32 scope global eth2 # плавающий IP-адрес VM_1
- Набор правил NAT настроен в iptables для плавающего IP. Ниже приведены все соответствующие записи из таблицы «nat» вычислительного узла (отрывок из команды: «
iptables –S -t nat». Подробную статью о том, как настроить NAT с помощью Linux iptables, можно найти здесь):# это правило гарантирует, что пакеты, исходящие от вычислительного узла # где находится экземпляр, будет достигать экземпляра через его плавающий IP: -A nova-network-ВЫХОД -d 91.207.16.144 / 32 -j DNAT - в пункт назначения 10.0.0.3 # гарантирует, что весь внешний трафик на плавающий IP # направлен на фиксированный IP-адрес экземпляра -A nova-network-PREROUTING -d 91.207.16.144/32 -j DNAT --to-destination 10.0.0.3 # весь трафик, исходящий от экземпляра, будет привязан к его плавающему IP по протоколу SNAT -A nova-network-float-snat -s 10.0.0.3/32 -j SNAT --to-source 91.207.16.144
В общем, nova-network добавляет несколько пользовательских цепочек к тем, которые предопределены в таблице NAT.Порядок этих цепочек относительно плавающего IP-трафика показан ниже (со ссылкой на правила, показанные выше):ВЫХОД ЦЕПИ - Цепочка nova-network-OUTPUT - Правило: -d 91.207.16.144/32 -j DNAT --to-destination 10.0.0.3
ПРЕПАРАТ ЦЕПИ - Цепочка nova-network-PREROUTING - Правило: -d 91.207.16.144/32 -j DNAT --to-destination 10.0.0.3
ПОСТРОУТИРОВАНИЕ ЦЕПИ - Цепочка nova-postrouting-bottom - Цепочка nova-network-snat - Цепочка nova-network-float-snat - Правило: -s 10.0.0.3 / 32 -j SNAT - к источнику 91.207.16.144
- Код, отвечающий за установку этих правил, находится в nova / network / linux_net.py в функции:
def правила_плавающего_передачи (плавающий_IP, фиксированный_IP): return [('PREROUTING', '-d% s -j DNAT --to% s'% (float_ip, fixed_ip)), ('ВЫВОД', '-d% s -j DNAT --to% s'% (плавающий_IP, фиксированный_IP)), ('поплавок', '-s% s -j SNAT --to% s'% (фиксированный_ип_плава, плавающий_ip))]
- Трафик попадает в открытый интерфейс вычислительного узла (eth2). DNAT выполняется в цепочке nova-network-PREROUTING, так что IP-адрес назначения пакетов изменяется с 91.207.16.144 на 10.0.0.3. Вычислительный узел
- сверяется со своей таблицей маршрутизации и видит, что у него есть сеть 10.0.0.0, доступная на интерфейсе br100 (отрывок из
«ip route show»вычислительного узла):10.0.0.0 / 24 отклонения br100
Таким образом, он направляет пакет на интерфейс br100, который затем достигает экземпляра.
- Поскольку адрес назначения не находится в локальной сети экземпляра, пакеты отправляются непосредственно на шлюз экземпляра по умолчанию, который имеет номер 10.0.0.1 (адрес устройства «br100» на вычислительном узле). Вычислительный узел
- проверяет свои таблицы маршрутизации и видит, что у него нет 8.8.8.8 в его напрямую подключенных сетях, поэтому он пересылает пакет на свой шлюз по умолчанию (который является основным адресом eth2 91.207.15.105 в данном случае).
- Пакет попадает в цепочку POSTROUTING и передается в цепочку nova-network-float-snat, где его исходный IP-адрес перезаписывается на плавающий IP-адрес экземпляра (91.207.16.144).
Заметки о безопасности
При использовании OpenStack системный администратор передает полный контроль над iptables демонам nova. Набор настраиваемых правил очень сложен и легко нарушается любыми внешними манипуляциями. Более того, каждый раз, когда демон nova-network перезапускается, он повторно применяет все правила в цепочках iptables, связанных с OpenStack.Если есть необходимость каким-либо образом изменить поведение iptables, это следует сделать, изменив код в соответствующих местах файла linux_net.py (для правил NAT это будет функция Floating_forward_rules). Также стоит отметить, что nova-network, похоже, никоим образом не отслеживает свои таблицы. Поэтому, если мы вручную отбросим некоторые правила из цепочек, связанных с OpenStack, они не будут исправлены до следующего перезапуска nova-network. Таким образом, системный администратор может легко случайно открыть нежелательный доступ к самому вычислительному узлу.Помните, что nova-network разместила плавающий IP-адрес в качестве вторичного адреса на eth2 и установила правила DNAT, которые направляют трафик на фиксированный IP-адрес экземпляра:-A nova-network-PREROUTING -d 91.207.16.144/32 -j DNAT --to-destination 10.0.0.3Таким образом, весь трафик, достигающий 91.207.16.144, эффективно переходит на 10.0.0.3. А теперь представим, что системный администратор ночью исправлял некоторые проблемы с сетевым подключением и случайно сбросил все правила NAT, набрав:
iptables –F –t натВышеупомянутое правило NAT было отброшено, но у eth2 все еще есть вторичный IP-адрес 91.207.16.144 на нем. Таким образом, мы все еще можем получить доступ к 91.207.16.144 из внешнего мира, но вместо обращения к экземпляру у нас теперь есть доступ к самому вычислительному узлу (IP-адрес назначения больше не DNAT, поскольку мы сбросили все правила NAT). Дыра будет открыта до следующего перезапуска процесса nova-network, который снова установит правила.
Настройка плавающих IP-адресов
Это флаги в nova.conf, которые влияют на поведение плавающих IP-адресов:# интерфейс, к которому привязаны плавающие IP-адреса # в качестве дополнительных адресов public_interface = "eth2" # пул, из которого по умолчанию берутся плавающие IP default_floating_pool = "паб" # мы можем автоматически добавлять плавающий ip к каждому порожденному экземпляру auto_assign_floating_ip = false
Заключительные ноты
Механизм плавающего IP-адреса, помимо прямого доступа к экземплярам в Интернет, дает пользователям облака некоторую гибкость.«Захватив» плавающий IP-адрес, пользователи облака могут перетасовать их (т. Е. Отсоединить и прикрепить их к разным экземплярам на лету), тем самым облегчая выпуск новых или обновленных выпусков кода и обновлений версии системы. Для системных администраторов это представляет потенциальную угрозу безопасности, поскольку базовый механизм (iptables) функционирует сложным образом и не имеет надлежащего мониторинга и аварийного переключения со стороны OpenStack. В этом проекте рассматривается надлежащий мониторинг состояния ресурсов в OpenStack. Поскольку он все еще помечен как «незавершенный», очень важно разрешить только программному обеспечению OpenStack касаться политик брандмауэра, а не вмешиваться в них вручную.farmceutica.co.uk Фрагменты художественной репродукции Моизеса Леви Прибрежная океанская дока 24×24 КАНВАС МОРСКОЙ ПЕЙЗАЖ
farmceutica.co.uk Фрагменты художественных репродукций Моизеса Леви Прибрежная океанская дока 24×24 КАНВАС МОРСКОЙ ПЕЙЗАЖ ХУДОЖЕСТВЕННЫЙ ПРИНТ- Home
- Art
- Art Prints
- Fragments by Moises Levy Coastal Ocean Dock 24×24 CANVAS SEASCAPE ART PRINT
Artist Canvas 20 mil, Edition Type: Open Edition: Size Type / Large Dimension:: Medium, Prints are яркий с плотным черным и ярким белым цветом. Тип печати:: Холст: Дата создания:: 2000-настоящее время.400 г / м2, внесено в список:: Дилер или реселлер: Стиль:: Реализм, водонепроницаемость и устойчивость к царапинам. очень прочный, до 30 дюймов, ярко-белое сатинированное покрытие из смеси хлопка и поли. Холст очень толстый и имеет переплетение 2 на 1 высшего качества. ХУДОЖЕСТВЕННАЯ ПЕЧАТЬ НА ХОЛСТЕ — Фрагменты Моисеса Леви Прибрежная океанская дока 24×24. Оригинал / Репродукция:: Репродукция произведения искусства: Тема: Морской пейзаж, отпечатанный водостойкими сольвентными чернилами.
Щелкните здесь, чтобы просмотреть последние новости
верхнийФрагменты Моисеса Леви Прибрежная океанская дока 24×24 КАНВАС МОРСКОЙ ПЕЙЗАЖ ИСКУССТВЕННЫЙ ПРИНТ
Эдвардианский пост королей британской армии, вербовка гвардейцев, печать формата А3.ПЕЙЗАЖ ВОДОПАД ВИРДЖИНИЯ США КРАСИВАЯ ПОЛЯНА БОЛЬШОЙ ИСКУССТВЕННЫЙ ПРИНТ BB3100A. Подробная информация о Рокки IV Рокки Бальбоа против Ивана Драго Бой Плакат / печать> Сталлоне> Лундгрен, серфинг на автобусе, серфинг на пляже кемперван, акварель, холст, картина, печать, живопись, Белый тигр, животное, искусство, плакат, холст, настенная печать, современное украшение гостиной, Ранняя Ниагара, поездка в Великое ущелье, иллюстрированная карта железной дороги Водопад Водоворот Рапидс, фотография вашего iPhone 10×45 дюймов, панорамное изображение / фотография в рамке, печать на холсте, Фрагменты от Moises Levy Coastal Ocean Dock 24×24 CANVAS SEASCAPE ART PRINT , ZA846 Мэрилин Монро Smile Now Skull Now Skull Tattoo Mink Blanket Queen Poster Hot 36×24, Custom 5200 Шелковый плакат Maxo Kream для декора стен.Матрос Джерри Тату Винтаж Холст Печать A0 A1 A2 A3 A4, 24×36 Караваджо Художественный постер Жертвоприношение Исаака, LINE UP АРЕСТ ПОСТЕР АРЕСТОВАННЫЙ РАЗВИТИЕ ТВ 1733 24×36, СКЕЙТБОРД ШЛИФОВАНИЕ ИСКРЫ НОВЫЙ ГИГАНТНЫЙ ПЛАКАТ НАСТЕННЫЙ АРТ ПЕЧАТЬ ИЗОБРАЖЕНИЕ X1405. Street Art George Clffiti Street Art George Clffiti. Домашний декор новый плакат. Фрагменты Моисеса Леви Прибрежная океанская дока 24×24 КАНВАС МОРСКОЙ ПЕЙЗАЖ ИСКУССТВЕННЫЙ ПРИНТ ,
ОСОБЕННОСТИ
FARMCEUTICA — поставщик каннабиноидных ингредиентов премиум-класса и партнер по реализации для Великобритании и других стратегических рынков ЕС.
Сосредоточен на
партнерства по выращиванию и добыче, производственные и стратегические каналы сбыта.
Подписанные контракты
поставляет продукцию ведущих британских производственных брендов с налаженными отношениями с розничной торговлей в сфере велнес и фармацевтики.
Развертывание нанотехнологий
для разработки новых продуктов и предложений под частными торговыми марками с запатентованной технологией доставки.
Использование существующих производственных мощностей
и установил доступ к другим ключевым производственным активам. Установлены глобальные каналы сбыта из Северной Америки в Европу.
Распределительные каналы
Прямые производители, оптовые торговцы и известные розничные бренды.
Бизнес модель
Белая этикетка и оптовые предложения для своевременной доставки, чтобы высвободить оборотный капитал для наших клиентов.Стабильность качества продукции и надежность поставок.
Преимущество Farmceutica
Предлагает продукцию высшего качества без тяжелых металлов и пестицидов. Поставка 99% + изолятов высокой чистоты и 90% + дистиллятов.
Честность и прозрачность
Полный контроль над цепочкой поставок с полным отслеживанием продуктов, обеспечение неизменного качества продукта через сторонние испытания в США и Великобритании.
Поставка
Наши поставки для теплиц обеспечивают полный контроль за окружающей средой, на которой выращивается конопля, для отслеживания и обеспечения стабильных результатов продукции.
Под ключ
Упрощенный единый источник для полного набора продуктов.
НАШ БРЕНД ОБЕЩАНИЕ
Мы стремимся дать нашим клиентам уверенность в том, что их продукция всегда будет доступна и неизменно высокого качества.
Мы предоставляем производителям и брендам каннабиноидные ингредиенты самого высокого качества, что позволяет им сосредоточиться на ведении и развитии собственного бизнеса, не конкурируя с собственной группой снабжения.
Семена на полку, мы — надежный партнер по ингредиентам
НАША ИСТОРИЯ
Сосредоточен на поиске и производстве сквозной, полностью интегрированной реализации бренда в масштабе с полным контролем над цепочкой поставок, полным отслеживанием продуктов, обеспечением неизменного качества продукта.
НАША МИССИЯ
FarmCeutica предоставляет платформу, которая обеспечивает быстрый и легкий выход на рынок, устраняя при этом высокие капитальные затраты на создание специализированных объектов для отдельных брендов и поддерживая стабильное качество продукции с индивидуальным исполнением продукции. Мы также помогаем брендам получить все необходимые регулирующие лицензии.
Мы предлагаем ряд продуктов премиум-класса без тяжелых металлов и пестицидов, включая изоляты высокой чистоты 99% + и дистилляты 90% +.Мы предлагаем услугу поставки точно в срок, следя за тем, чтобы наши клиенты не вносили предоплату за свой продукт до того, как он будет произведен или отправлен. Они платят только после того, как товар будет бесплатно доставлен в Великобританию.
Наши клиенты активно участвуют и влияют на нашу цепочку поставок, вплоть до генетики семян. Мы можем предоставить полную документацию по цепочке поставок нашего продукта.
У нас есть стратегические и лояльные партнеры по лабораториям, которые обеспечивают стабильные поставки, поскольку мы поставляем стабильное сырье, которое требует минимальной повторной калибровки партии за партией.
Наши поставки основаны на теплицах. Когда вы контролируете окружающую среду растения конопли, вы можете легче контролировать результаты.
Фрагменты Моисеса Леви Прибрежная океанская дока 24×24 КАНВАС МОРСКОЙ ПЕЙЗАЖ ИСКУССТВЕННЫЙ ПРИНТ
Coastal Ocean Dock 24×24 КАНВАС SEASCAPE ART PRINT Фрагменты Моизеса Леви, высокопрочные, водонепроницаемые и устойчивые к царапинам, холст Artist Canvas 20 мил (400 г / м2) с атласной отделкой из смеси хлопка и поли, напечатанный водостойкими сольвентными чернилами. плотный черный и яркий белый, холст очень толстый и может похвастаться высококачественным переплетением 2 на 1, всемирно известным сайтом моды, стильным дизайном, отличным сервисом и простым способом заказа.Фрагменты Моисеса Леви Прибрежный океанский причал 24×24 ХУДОЖЕСТВЕННЫЙ ПРИНТ НА МОРЕЙСКОМ ПЕЙЗАЖЕ, Фрагменты Моисеса Леви Прибрежный океанский причал 24×24 КАНВАС ИСКУССТВЕННЫЙ ПЕЙЗАЖ.
WordPress и LAMP в контейнере LXC
| Контейнер |
Мне нужно протестировать HTML-код, работающий в WordPress.
Но я не использую WordPress … очевидно.
В Linux это легко исправить. Просто установите WordPress.
Ой, не все так просто: WordPress втягивает с собой весь стек LAMP.
Это слишком много, чтобы загрязнить мой ноутбук, просто чтобы провести небольшое тестирование.
Контейнеры спешат на помощь!
Давайте развернем контейнер, установим в него LAMP и WordPress, запустим тесты, а затем уничтожим контейнер.
| Грузовые |
Маршрутизатор
Я собираюсь открыть для этого совершенно новый порт на брандмауэре моего маршрутизатора, чтобы другие могли помочь мне в тестировании.
На маршрутизаторе я хочу перенаправить порт 112233 на аналогичный порт на сервере.
На сервере я хочу перенаправить порт 112233 на порт 80 контейнера (эта часть будет позже)
Создание контейнера
Спасибо замечательному Стефану Граберу за его подробную серию инструкций о том, как создать и использовать контейнер. Это немного другая установка, чем он. Вместо установки, скажем, непосредственно на ноутбук, я устанавливаю контейнер на сервер, к которому я обращаюсь через ssh.
Три движущихся части: Ноутбук (я), Сервер (без головы), Контейнер (добавлен к серверу)
Итак, с портативного компьютера я обычно подключаюсь к серверу по ssh.
На СЕРВЕРЕ:
sudo apt-get install lxc # Установить контейнерную систему
sudo lxc-create -t ubuntu-cloud -n c1 # Загрузите и установите облачный образ Ubuntu 14.10 размером 195 МБ
sudo lxc-start -n wp1 -d # Загрузить изображение в фоновом режиме (имя - 'wp1')
sudo lxc-info -n wp1 # Узнать IP-адрес образа
Имя: c1
Состояние: РАБОТАЕТ
IP: 10.0.3.201 # <- Ой, вот и IP
ping 10.0.3.201 # Проверить сетевое подключение на контейнере
ПИНГ 10.0.3.201 (10.0.3.201) 56 (84) байтов данных.
64 байта из 10.0.3.201: icmp_seq = 1 ttl = 64 time = 0,081 мс
64 байта из 10.0.3.201: icmp_seq = 2 ttl = 64 time = 0,085 мс
# Перенаправить порт 112233 в контейнер
sudo iptables -t nat -A PREROUTING -p tcp -i eth0 --dport 112233 -j DNAT --to-destination 10.0.3.201:80
sudo iptables -A FORWARD -p tcp -d 10.0.3.201 --dport 80 -m state --state NEW, ESTABLISHED, RELATED -j ACCEPT Настройте LAMP и WordPress в контейнере
Контейнер установлен, запускается и отвечает на пинг.
НА СЕРВЕРЕ: sudo lxc-console -n wp1 # Войдите в консоль wp1 (имя пользователя: ubuntu, пароль: ubuntu)
Пару слов о таре.
Я пропущу часть, в которой вы должны удалить пользователя ubuntu и добавить своего собственного пользователя и пароль администратора. Но ты должен это сделать.
Кроме того, вам следует иметь под рукой две части информации, прежде чем двигаться дальше.
- IP-адрес сервера в локальной сети (у меня 192.168.0.101)
- Настоящее полное доменное имя (freds_blog.fred.com), что читатели в Интернете будут использовать
Особая благодарность сообществу Ubuntu за составление этого фантастического руководства о том, как установить wordpress в Ubuntu.
# НА КОНТЕЙНЕРЕ sudo apt-get install mysql-server wordpress # 49 packages, 28MB скачать
Давайте на мгновение перейдем к ноутбуку и проверим, что перенаправление портов сервера и служба apache контейнера работают: откройте окно браузера и найдите http: // 192.168.0.101: 112233. Вы должны получить страницу apache по умолчанию. Успех! Хорошо, теперь вернемся к контейнеру:
# В КОНТЕЙНЕРЕ
sudo ln -s / usr / share / wordpress / var / www / html / wordpress # Сделать WordPress доступным из apache # Создать учетную запись mysql и связать ее с WordPress sudo gzip -d /usr/share/doc/wordpress/examples/setup-mysql.gz sudo bash / usr / share / doc / wordpress / examples / setup-mysql -n freds_blog_fred_com freds_blog.fred.com # Предотвратить ошибку WordPress (не удается найти файл конфигурации) из локальной сети # путем связывания адреса LAN с существующим файлом конфигурации FQDN sudo ln / etc / wordpress / config-freds_blog.fred.com.php /etc/wordpress/config-192.168.0.101.php выходдля выхода из консоли
Используйте WordPress
Настройка завершена. Поскольку я нахожусь в своей локальной сети, я указываю в браузере ноутбука на http://192.168.1.101/wordpress/ и получаю экран настройки WordPress.
Снаружи, в большом широком Интернете, я бы указал на http://freds_blog.fred.com/wordpress/ (э-э, это пример - вы, , уже знаете, что - это не мой настоящий блог).
WordPress готов для моих данных.
| Пока, контейнер! |
Уничтожение контейнера
Это одна из истинных радостей LXC
# На СЕРВЕРЕ sudo lxc-stop -n wp1 sudo lxc-destroy -n wp1
И вся работа стерта навсегда ....
Не забудьте очистить:
- Удалите lxc с сервера
- Удалить правила iptables на сервере
- Закройте порт на межсетевом экране маршрутизатора
Как настроить и использовать LXD в Ubuntu 16.04
В этой статье используется Ubuntu 16.04.
Срок службы этого дистрибутива подошел к концу (EOL) в апреле 2021 года. Ubuntu 16.04
Введение
Контейнер Linux - это группа процессов, которая изолирована от остальной системы за счет использования функций безопасности ядра Linux, таких как пространства имен и группы управления. Эта конструкция похожа на виртуальную машину, но намного легче; у вас нет накладных расходов на запуск дополнительного ядра или имитацию оборудования.Это означает, что вы можете легко создать несколько контейнеров на одном сервере.
Например, представьте, что у вас есть сервер, на котором работает несколько веб-сайтов для ваших клиентов. При традиционной установке каждый веб-сайт будет виртуальным хостом одного и того же экземпляра веб-сервера Apache или Nginx. Но с контейнерами Linux каждый веб-сайт может быть настроен в своем собственном контейнере со своим собственным веб-сервером. Используя контейнеры Linux, вы объединяете свое приложение и его зависимости в контейнер, не затрагивая остальную систему.
LXD позволяет создавать эти контейнеры и управлять ими. LXD предоставляет услугу гипервизора для управления всем жизненным циклом контейнеров. В этом руководстве вы настроите LXD и используете его для запуска Nginx в контейнере. Затем вы направите трафик в контейнер, чтобы сделать веб-сайт доступным из Интернета.
Предварительные требования
Для выполнения этого руководства вам понадобится следующее:
Шаг 1 - Настройка LXD
LXD уже установлен в Ubuntu, но его необходимо правильно настроить, прежде чем вы сможете использовать его на сервере.Вы должны настроить свою учетную запись для управления контейнерами, затем настроить тип серверной части хранилища для хранения контейнеров и настроить сеть.
Войдите на сервер, используя учетную запись пользователя без полномочий root. Затем добавьте своего пользователя в группу lxd , чтобы вы могли использовать его для выполнения всех задач по управлению контейнерами:
- sudo usermod --append --groups lxd sammy
Выйдите из сервера и войдите снова, чтобы ваш новый сеанс SSH был обновлен с учетом нового членства в группе.После входа в систему вы можете приступить к настройке LXD.
Теперь настройте серверную часть хранилища. Для LXD рекомендуется использовать файловую систему ZFS, которая хранится либо в заранее выделенном файле, либо в блочном хранилище. Чтобы использовать поддержку ZFS в LXD, обновите список пакетов и установите zfsutils-linux package:
- sudo apt-get update
- sudo apt-get install zfsutils-linux
Теперь вы можете настроить LXD.Запустите процесс инициализации LXD с помощью команды lxd init :
Вам будет предложено указать сведения о серверной части хранилища. После завершения этой настройки вы настроите сеть для контейнеров.
Сначала вас спросят, хотите ли вы настроить новый пул хранения. Вы должны ответить да. .
Хотите настроить новый пул хранения (да / нет) [по умолчанию = да]? да
Затем вам будет предложено указать серверную часть хранилища, и вам будет предложено два варианта: dir или zfs .Параметр dir указывает LXD хранить контейнеры в каталогах файловой системы сервера. Опция zfs использует комбинированную файловую систему ZFS и диспетчер логических томов.
Мы будем использовать опцию zfs . Используя zfs , мы получаем как эффективность хранения, так и лучшую скорость отклика. Например, если мы создадим десять контейнеров из одного и того же исходного образа контейнера, все они будут использовать дисковое пространство только одного образа контейнера. С этого момента в бэкэнде хранилища будут храниться только их изменения в исходном образе контейнера.
Выходные данные
Имя используемой серверной части хранилища (dir или zfs) [default = zfs]: zfs
После выбора zfs вам будет предложено создать новый пул ZFS и дать ему имя. Выберите да , чтобы создать пул, и вызовите пул lxd :
Выходные данные
Создать новый пул ZFS (да / нет) [по умолчанию = да]? да
Имя нового пула ZFS [по умолчанию = lxd]: lxd
Затем вас спросят, хотите ли вы использовать существующее блочное устройство:
Выход
Хотите использовать существующее блочное устройство (да / нет) [по умолчанию = нет]?
Если вы ответите да , вам нужно будет сообщить LXD, где найти это устройство.Если вы скажете нет , LXD будет использовать предварительно выделенный файл. С этой опцией вы будете использовать свободное место на самом сервере.
Далее следуют два раздела, в зависимости от того, хотите ли вы использовать предварительно выделенный файл или блочное устройство. Следуйте шагу, соответствующему вашему случаю. После того, как вы указали механизм хранения, вы настроите сетевые параметры для своих контейнеров.
Вариант 1. Использование предварительно выделенного файла
Вы можете использовать предварительно выделенный файл, если у вас нет доступа к отдельному устройству хранения блоков для хранения контейнеров.Выполните следующие действия, чтобы настроить LXD на использование предварительно выделенного файла для хранения контейнеров.
Сначала, когда вас попросят использовать существующее блочное устройство, введите № :
Выход
Хотите использовать существующее блочное устройство (да / нет) [по умолчанию = нет]? нет
Затем вас попросят указать размер устройства петли , что LXD называет предварительно выделенным файлом.
Используйте рекомендуемый размер по умолчанию для предварительно выделенного файла:
Выходные данные
Размер нового кольцевого устройства в ГБ (минимум 1 ГБ) [по умолчанию = 15]: 15
Как показывает практика, 15 ГБ - это самый маленький размер, который вы должны создать; вы хотите заранее выделить достаточно места, чтобы у вас было не менее 10 ГБ свободного места после создания контейнеров.
После настройки устройства вам будет предложено настроить параметры сети. Перейдите к шагу 2, чтобы продолжить настройку.
Вариант 2 - Использование блочного устройства
Если вы собираетесь использовать блочное хранилище в качестве внутреннего хранилища, вам необходимо найти устройство, которое указывает на созданный вами том блочного хранилища, чтобы указать его в конфигурации LXD. Перейдите на вкладку Volumes на панели управления DigitalOcean, найдите свой том, щелкните всплывающее окно More , а затем щелкните инструкции по настройке .
Найдите устройство, просмотрев команду форматирования тома. В частности, ищите путь, указанный в команде sudo mkfs.ext4 -F . Не запускайте никакие команды с этой страницы, так как нам просто нужно найти правильное имя устройства, которое нужно передать LXD. На следующем рисунке показан пример имени устройства тома. Вам понадобится только та часть, которая подчеркнута красной линией:
Вы также можете определить имя устройства с помощью следующей команды:
- ls -l / dev / disk / by-id /
- Всего 0
- lrwxrwxrwx 1 корень root 9 сен 16 20:30 scsi-0DO_Volume_volume-fra1-01 ->../../sda
-
В данном случае имя устройства для тома - / dev / disk / by-id / scsi-0D0_Volume_volume-fra1-01 , хотя ваше имя может отличаться.
После того, как вы определите имя устройства для тома, продолжите установку LXD. Когда вам будет предложено использовать существующее блочное устройство, выберите да и укажите путь к вашему устройству:
Вывод команды «lxd init»
Хотите использовать существующее блочное устройство (да / нет) [по умолчанию = нет]? да
Путь к существующему блочному устройству: / dev / disk / by-id / scsi-0DO_Volume_volume-fra1-01
После того, как вы укажете диск, вам будет предложено настроить параметры сети.
Шаг 2 - Настройка сети
После настройки серверной части хранилища вам будет предложено настроить сеть для LXD.
Сначала LXD спрашивает, хотите ли вы сделать его доступным по сети. Выбор да позволит вам управлять LXD с локального компьютера без необходимости подключаться к этому серверу по SSH. Оставьте значение по умолчанию нет :
Вывод команды «lxd init» - LXD по сети
Хотите, чтобы LXD был доступен по сети (да / нет) [по умолчанию = нет]? нет
Если вы хотите включить эту опцию, прочтите LXD 2.0: удаленные хосты и миграция контейнеров, чтобы узнать больше.
Затем нас просят настроить сетевой мост для контейнеров LXD. Это позволяет использовать следующие функции:
- Каждый контейнер автоматически получает частный IP-адрес.
- Контейнеры могут связываться друг с другом по частной сети.
- Каждый контейнер может инициировать подключения к Интернету.
- Создаваемые вами контейнеры остаются недоступными из Интернета; вы не можете установить соединение из Интернета и получить доступ к контейнеру, если вы явно не включите его.На следующем шаге вы узнаете, как разрешить доступ к определенному контейнеру.
Когда вас попросят настроить мост LXD, выберите да :
Вывод команды «lxd init» - Сеть для контейнеров
Вы хотите настроить мост LXD (да / нет) [по умолчанию = да]? да
Затем вы увидите следующее диалоговое окно:
Подтвердите, что вы хотите настроить сетевой мост.
Вам будет предложено назвать мост.Примите значение по умолчанию.
Вам будет предложено выполнить настройку сети как для IPv4, так и для IPv6. В этом руководстве мы будем работать только с IPv4.
Когда вас попросят настроить подсеть IPv4, выберите Да . Вам сообщат, что он настроил для вас случайную подсеть. Выберите Ok , чтобы продолжить.
При запросе действительного адреса IPv4 примите значение по умолчанию.
При запросе действительной маски CIDR примите значение по умолчанию.
При запросе первого адреса DHCP примите значение по умолчанию. Сделайте то же самое для последнего адреса DHCP, а также для максимального количества клиентов DHCP.
Выберите Да при запросе NAT для трафика IPv4.
Когда будет предложено настроить подсеть IPv6, выберите Нет . После завершения настройки сети вы увидите следующий результат:
Выход
Предупреждение: остановка lxd.service, но ее все еще можно активировать:
lxd.разъем
LXD успешно настроен.
Вы готовы создавать свои контейнеры.
Шаг 3 - Создание контейнера Nginx
Вы успешно настроили LXD и теперь готовы создавать свой первый контейнер и управлять им. Вы управляете контейнерами с помощью команды lxc .
Используйте lxc list для просмотра доступных установленных контейнеров:
Вы увидите следующий результат:
Вывод команды "lxd list"
Создание сертификата клиента.Это может занять минуту ...
Если вы впервые используете LXD, вам также следует запустить: sudo lxd init
Чтобы запустить свой первый контейнер, попробуйте: lxc launch ubuntu: 16.04
+ ------ + ------- + ------ + ------ + ------ + ----------- +
| ИМЯ | ГОСУДАРСТВО | IPV4 | IPV6 | ТИП | СНИМКИ |
+ ------ + ------- + ------ + ------ + ------ + ----------- +
Поскольку это первый раз, когда команда lxc взаимодействует с гипервизором LXD, выходные данные позволяют узнать, что команда автоматически создала сертификат клиента для безопасной связи с LXD.Затем он показывает некоторую информацию о том, как запустить контейнер. Наконец, команда показывает пустой список контейнеров, чего и следовало ожидать, поскольку мы еще не создали ни одного.
Давайте создадим контейнер, в котором работает Nginx. Для этого воспользуемся командой lxc launch , чтобы создать и запустить контейнер Ubuntu 16.04 с именем webserver .
Создайте веб-сервер контейнер:
- lxc запустить веб-сервер ubuntu: x
x в ubuntu: x - это ярлык для первой буквы Xenial, кодового имени Ubuntu 16.04. ubuntu: - это идентификатор предварительно настроенного репозитория образов LXD. Вы также можете использовать ubuntu: 16.04 в качестве имени образа.
Примечание : Вы можете найти полный список всех доступных образов Ubuntu, запустив lxc image list ubuntu: и другие дистрибутивы, запустив lxc image list images: .
Поскольку контейнер создается впервые, эта команда загружает образ контейнера из Интернета и кэширует его локально, чтобы при создании нового контейнера он создавался быстрее.При создании нового контейнера вы увидите этот результат:
Выходные данные
Создание сертификата клиента. Это может занять минуту ...
Если вы впервые используете LXD, вам также следует запустить: sudo lxd init
Чтобы запустить свой первый контейнер, попробуйте: lxc launch ubuntu: 16.04
Создание веб-сервера
Получение изображения: 100%
Запуск веб-сервера
Теперь, когда контейнер запущен, используйте команду lxc list , чтобы отобразить информацию о нем:
В выходных данных отображается таблица с именем каждого контейнера, его текущим состоянием, IP-адресом, типом и тем, были ли сделаны снимки.
Выход
+ ----------- + --------- + ---------------------- - + ------ + ------------ + ----------- +
| ИМЯ | ГОСУДАРСТВО | IPV4 | IPV6 | ТИП | СНИМКИ |
+ ----------- + --------- + ----------------------- + --- --- + ------------ + ----------- +
| веб-сервер | РАБОТАЕТ | 10.10.10.100 (eth0) | | УСТОЙЧИВОСТЬ | 0 |
+ ----------- + --------- + ----------------------- + --- --- + ------------ + ----------- +
Примечание: Если вы включили IPv6 в LXD, вывод команды lxc list может быть слишком широким для вашего экрана.Вместо этого вы можете использовать lxc list --columns ns4tS , который показывает только имя, состояние, IPv4, тип и наличие доступных снимков.
Запишите IPv4-адрес контейнера. Он понадобится вам, чтобы настроить брандмауэр, чтобы разрешить трафик из внешнего мира.
Теперь давайте настроим Nginx внутри контейнера:
Шаг 4 - Настройка контейнера Nginx
Давайте подключимся к контейнеру webserver и настроим веб-сервер.
Подключиться к контейнеру с помощью команды lxc exec , которая принимает имя контейнера и команды для выполнения:
- lxc exec веб-сервер - sudo --login --user ubuntu
Первая строка - означает, что параметры команды для lxc должны на этом останавливаться, а остальная часть строки будет передана как команда, которая будет выполняться внутри контейнера. Это команда sudo --login --user ubuntu , которая предоставляет оболочку входа для предварительно настроенной учетной записи ubuntu внутри контейнера.
Примечание: Если вам нужно подключиться к контейнеру как root , используйте вместо этого команду lxc exec webserver - / bin / bash .
Внутри контейнера приглашение оболочки теперь выглядит следующим образом.
Вывод
ubuntu @ webserver: ~ $
Этот пользователь ubuntu в контейнере имеет предварительно настроенный доступ sudo и может запускать команды sudo без ввода пароля.Эта оболочка ограничена пределами контейнера. Все, что вы запускаете в этой оболочке, остается в контейнере и не может уйти на хост-сервер.
Давайте настроим Nginx в этом контейнере. Обновите список пакетов экземпляра Ubuntu внутри контейнера и установите Nginx:
- sudo apt-get update
- sudo apt-get install nginx
Затем отредактируйте веб-страницу по умолчанию для этого сайта и добавьте текст, поясняющий, что этот сайт размещен в контейнере веб-сервера .Откройте файл /var/www/html/index.nginx-debian.html :
- sudo nano /var/www/html/index.nginx-debian.html
Внесите в файл следующие изменения:
Отредактированный файл /var/www/html/index.nginx-debian.html
Добро пожаловать в nginx на веб-сервере контейнера LXD!
<стиль>
тело {
ширина: 35em;
маржа: 0 авто;
семейство шрифтов: Tahoma, Verdana, Arial, sans-serif;
}
Добро пожаловать в nginx на веб-сервере контейнера LXD!
Если вы видите эту страницу, веб-сервер nginx успешно установлен и
работающий.Требуется дополнительная настройка.
...
Мы отредактировали файл в двух местах и специально добавили текст на веб-сервере контейнера LXD . Сохраните файл и выйдите из редактора.
Теперь выйдите из контейнера и вернитесь на хост-сервер:
Используйте curl , чтобы проверить, что веб-сервер в контейнере работает. Вам потребуются IP-адреса веб-контейнеров, которые вы нашли ранее с помощью команды lxd list .
- завиток http://10.10.10.100/
Результат должен быть:
Вывод
Добро пожаловать в nginx на веб-сервере контейнера LXD!
<стиль>
тело {
ширина: 35em;
маржа: 0 авто;
семейство шрифтов: Tahoma, Verdana, Arial, sans-serif;
}
Добро пожаловать в nginx на веб-сервере контейнера LXD!
Если вы видите эту страницу, веб-сервер nginx успешно установлен и
работающий.Требуется дополнительная настройка.
...
Веб-сервер работает, но мы можем получить к нему доступ только через частный IP. Давайте направим внешние запросы в этот контейнер, чтобы весь мир мог получить доступ к нашему веб-сайту.
Шаг 5 - Перенаправление входящих подключений к контейнеру Nginx
Последний кусок головоломки - подключить контейнер веб-сервера к Интернету. Nginx устанавливается в контейнере и по умолчанию недоступен из Интернета.Нам необходимо настроить наш сервер для пересылки любых подключений, которые он может получать из Интернета на порт 80 , в контейнер веб-сервера . Для этого мы создадим правило iptables для пересылки соединений. Вы можете узнать больше о IPTables в разделах «Как работает брандмауэр IPtables» и «IPtables Essentials: общие правила и команды брандмауэра».
Для команды iptables требуются два IP-адреса: общедоступный IP-адрес сервера ( your_server_ip ) и частный IP-адрес контейнера nginx ( your_webserver_container_ip ), которые можно получить с помощью списка lxc команда.
Выполните эту команду, чтобы создать правило:
- PORT = 80 PUBLIC_IP = your_server_ip CONTAINER_IP = your_container_ip \
- sudo -E bash -c 'iptables -t nat -I PREROUTING -i eth0 -p TCP -d $ PUBLIC_IP --dport $ PORT -j DNAT --to-destination $ CONTAINER_IP: $ PORT -m comment --comment "вперед в контейнер Nginx" '
Вот как разбивается команда:
-
-t natуказывает, что мы используем таблицуnatдля преобразования адресов. -
-I PREROUTINGуказывает, что мы добавляем правило в цепочку PREROUTING. -
-i eth0указывает интерфейс eth0 , который является общедоступным интерфейсом по умолчанию для капель. -
-p TCPговорит, что мы используем протокол TCP. -
-d $ PUBLIC_IPуказывает IP-адрес назначения для правила. -
--dport $ PORT: указывает порт назначения (например,80). -
-j DNATговорит, что мы хотим выполнить переход к NAT назначения (DNAT). -
--to-destination $ CONTAINER_IP: $ PORTговорит, что мы хотим, чтобы запрос шел на IP-адрес конкретного контейнера и порта назначения.
Примечание: Вы можете повторно использовать эту команду для настройки правил пересылки, просто установив переменные PORT , PUBLIC_IP и CONTAINER_IP в начале строки. Просто измените выделенные значения.
Вы можете вывести список правил IPTables, выполнив эту команду:
- sudo iptables -t nat -L ПЕРЕДАЧА
Вы увидите следующий результат:
Выход
ПЕРЕРАБОТКА ЦЕПИ (ПРИНЯТЬ политику)
target prot opt источник назначения
DNAT tcp - где угодно your_server_ip tcp dpt: http / * пересылать в этот контейнер * / to: your_container_ip: 80
...
Теперь проверьте, действительно ли веб-сервер доступен из Интернета, получив к нему доступ с локального компьютера с помощью команды curl , например:
- curl --verbose 'http: // your_server_ip'
Вы увидите заголовки, за которыми следует содержимое веб-страницы, созданной в контейнере:
Вывод
* Пробуем your_server_ip...
* Подключен к your_server_ip (your_server_ip) порт 80 (# 0)
> GET / HTTP / 1.1
> Пользовательский агент: curl / 7.47.0
> Принять: * / *
>
Добро пожаловать в nginx на веб-сервере контейнера LXD!
<стиль>
тело {
...
Это подтверждает, что запросы отправляются в контейнер.
Наконец, чтобы сохранить правило брандмауэра для его повторного применения после перезагрузки, установите пакет iptables-persistent :
- sudo apt-get install iptables-persistent
При установке пакета вам будет предложено сохранить текущие правила брандмауэра.Примите и сохраните все текущие правила.
При перезагрузке машины правило брандмауэра будет присутствовать. Кроме того, служба Nginx в вашем контейнере LXD автоматически перезапустится.
Теперь, когда вы все настроили, давайте посмотрим, как это разобрать.
Шаг 5 - Остановка и извлечение контейнера
Вы можете решить снять контейнер и заменить его. Давайте рассмотрим этот процесс:
Чтобы остановить контейнер, используйте lxc stop :
Используйте команду lxc list для проверки состояния.
Выход
+ ----------- + --------- + ------ + ------ + -------- ---- + ----------- +
| ИМЯ | ГОСУДАРСТВО | IPV4 | IPV6 | ТИП | СНИМКИ |
+ ----------- + --------- + ------ + ------ + ------------ + ----------- +
| веб-сервер | ОСТАНОВЛЕННЫЙ | | | УСТОЙЧИВОСТЬ | 0 |
+ ----------- + --------- + ------ + ------ + ------------ + ----------- +
Чтобы удалить контейнер, используйте lxc delete :
Запуск lxc list снова показывает, что контейнер не запущен:
Выход
+ ------ + ------- + ------ + ------ + ------ + -------- --- +
| ИМЯ | ГОСУДАРСТВО | IPV4 | IPV6 | ТИП | СНИМКИ |
+ ------ + ------- + ------ + ------ + ------ + ----------- +
Используйте команду lxc help для просмотра дополнительных параметров.
Чтобы удалить правило брандмауэра, которое направляет трафик в контейнер, сначала найдите правило в списке правил с помощью этой команды, которая связывает номер строки с каждым правилом:
- sudo iptables -t nat -L PREROUTING --line-numbers
Вы увидите свое правило с префиксом номера строки, например:
Выход
ПЕРЕРАБОТКА ЦЕПИ (ПРИНЯТЬ политику)
num target prot opt источник назначения
1 DNAT tcp - в любом месте your_server_ip tcp dpt: http / * пересылать в контейнер Nginx * / в: your_container_ip
Используйте этот номер строки, чтобы удалить правило:
- sudo iptables -t nat -D PREROUTING 1
Убедитесь, что правило отменено, снова перечислив правила:
`sudo iptables -t nat -L PREROUTING --line-numbers`
Правило исчезнет:
Выход
ПЕРЕРАБОТКА ЦЕПИ (ПРИНЯТЬ политику)
num target prot opt источник назначения
Теперь сохраните изменения, чтобы правило не возвращалось при перезапуске сервера:
- sudo netfilter-постоянное сохранение
Теперь вы можете вызвать другой контейнер со своими настройками и добавить новое правило брандмауэра для перенаправления в него трафика.
Заключение
Вы создали веб-сайт с помощью Nginx, работающего в контейнере LXD. Отсюда вы можете настроить больше веб-сайтов, каждый из которых будет ограничен своим собственным контейнером, и использовать обратный прокси-сервер для направления трафика в соответствующий контейнер. В руководстве «Как разместить несколько веб-сайтов с помощью Nginx и HAProxy с использованием LXD в Ubuntu 16.04» вы узнаете, как это настроить.
LXD также позволяет делать снимки полного состояния контейнеров, что упрощает создание резервных копий и откат контейнеров в более позднее время.А если вы установите LXD на два разных сервера, то можно будет соединить их и перенести контейнеры между серверами через Интернет.
Подробнее о LXD см. В этой серии сообщений в блоге о LXD 2.0, написанных сопровождающим LXD.
Вы также можете попробовать LXD в Интернете и следовать веб-руководству, чтобы получить больше практики.
Подключаемый модуль ультрафиолетового света привлекает насекомыхЭта липкая ловушка, защищающая до 600 квадратных футов, быстро избавит ваше жизненное пространство от летающих насекомых, которые могут переносить бактерии и болезни, включая комаров, плодовых мух, моли и т. Д.Используя эксклюзивную технологию AtraktaGlo, Flylight излучает мягкий синий свет, которому не могут сопротивляться летающие насекомые. | StickyTech Glue ловушки насекомыхКлеевые карты StickyTech ловушки улавливают летающих насекомых. Мертвых насекомых незаметно скрывает алюминиевая крышка ловушки.Flylight поставляется с тремя сменными клеевыми картами StickyTech. Выбрасывайте и заменяйте клейкие карты каждые 30-60 дней или когда карта полностью покрыта. | Элегантный дизайн с двумя розетками переменного токаЭта ультрафиолетовая ловушка для мух имеет привлекательный дизайн, напоминающий бра, с классической белой отделкой.Мягкий свет AtraktaGlo работает как эффективный ночник в спальнях, ванных комнатах и коридорах. А благодаря двум сквозным розеткам переменного тока - по одной с каждой стороны устройства - вы можете подключать другие устройства во время использования Flylight. | Легкая установка в любой комнатеFlylight подключается к любой стандартной розетке на 120 вольт и покрывает площадь до 600 квадратных футов.Добавьте дополнительные фонари Flylight (продаются отдельно), чтобы защитить весь дом. Для достижения наилучших результатов заменяйте УФ-лампу AtraktaGlo каждые 3000 часов или примерно четыре месяца. Flylight имеет размеры 2,81 на 8,31 на 12,88 дюйма и вес 0,73 фунта. |
Как использовать брандмауэр UFW в Debian, Ubuntu, Linux Mint
Это руководство покажет вам, как использовать UFW (несложный FireWall) в Debian / Ubuntu / Linux Mint с некоторыми примерами из реальной жизни.Управление брандмауэром - это базовый навык, который должен знать каждый системный администратор. Эта статья предназначена для ознакомления читателя с UFW, но не исследует все тонкости UFW.
UFW - это интерфейс для iptables, упрощающий управление брандмауэром Netfilter, отсюда и название «Несложный брандмауэр». Он предоставляет интерфейс командной строки с синтаксисом, аналогичным пакетному фильтру OpenBSD. Он особенно хорошо подходит в качестве межсетевого экрана на базе хоста. UFW является рекомендуемым интерфейсом iptables в дистрибутивах Linux на основе Debian и обычно предварительно устанавливается в этих дистрибутивах.По умолчанию UFW устанавливает правила брандмауэра для адресов IPv4 и IPv6. Другой хорошо известный интерфейс iptables - это firewalld , который является брандмауэром по умолчанию в дистрибутивах Linux на основе RPM (RHEL, CentOS, Fedora, OpenSUSE и т. Д.).
Отключение других служб восстановления Iptables
Как вы, вероятно, знаете, правила брандмауэра iptables сбрасываются при завершении работы ОС, а сама программа iptables не восстанавливает правила брандмауэра. UFW по умолчанию восстанавливает правила брандмауэра после перезагрузки системы.Перед использованием UFW важно проверить, есть ли в вашей системе другая служба восстановления iptables. Если есть две службы восстановления, они будут конфликтовать друг с другом, что часто приводит к тому, что веб-приложения становятся недоступными после перезагрузки системы.
Если вы использовали брандмауэр iptables напрямую и теперь хотите переключиться на UFW, вам просто нужно отключить службу восстановления iptables. Iptables-persistent - хорошо известная служба восстановления iptables в Debian / Ubuntu.Вы можете проверить, работает ли он, с помощью следующей команды.
статус systemctl iptables-persistent
Если он запущен, его можно остановить и отключить.
sudo systemctl остановить iptables-persistent sudo systemctl отключить iptables-persistent
Или вы можете удалить его из своей системы.
sudo apt удалить iptables-persistent
Если вы настроили свой почтовый сервер с помощью iRedMail, обязательно выполните следующую команду, чтобы проверить, запущена ли служба iptables .
статус systemctl iptables
Эта служба iptables поставляется с iRedMail для восстановления правил брандмауэра iptables. Если он запущен, вы можете остановить и отключить его.
sudo systemctl stop iptables sudo systemctl отключить iptables
Теперь давайте узнаем, как использовать UFW.
Начало работы с UFW на сервере Debian / Ubuntu / Linux Mint
UFW обычно предустановлен на Debian / Ubuntu / Linux Mint, хотя вы всегда можете выполнить следующую команду, чтобы установить его.
sudo apt install ufw
Примечание. Вы можете установить UFW в Arch Linux с помощью sudo pacman -S ufw , но вам также необходимо включить службу UFW systemd с помощью sudo systemctl enable ufw .
При установке ufw отключен. Вы можете проверить статус UFW по номеру:
sudo ufw статус
UFW поставляется с входящей политикой по умолчанию deny , политикой пересылки по умолчанию deny и исходящей политикой по умолчанию allow , с отслеживанием состояния для новых соединений для входящих и перенаправленных соединений.Перед включением UFW вам необходимо знать, какие порты открыты на общедоступном IP-адресе вашего сервера, что можно получить с помощью nmap (Network Mapper).
Установите nmap на свой сервер Debian / Ubuntu / Linux Mint и просканируйте открытые порты на общедоступном IP-адресе.
sudo apt установить nmap sudo nmap 12.34.56.78
Замените 12.34.56.78 фактическим общедоступным IP-адресом вашего сервера. Как видно на скриншоте ниже, на моем сервере несколько открытых портов.
Есть также открытые порты, которые прослушивают только localhost, которые можно получить, запустив sudo nmap localhost , но нам не нужно о них беспокоиться.
Nmap по умолчанию сканирует только TCP-порты. Мы можем использовать следующую команду для сканирования портов UDP.
судо nmap -sU 12.34.56.78
Однако сканирование UDP ужасно медленное. Если вы не можете ждать так долго, вы можете использовать netstat для вывода списка портов UDP.
судо netstat -lnpu
После получения открытых портов TCP и UDP на вашем сервере, вам необходимо решить, какие порты должны быть разрешены для приема входящих подключений.Если запущен сервер openSSH, вы всегда должны разрешать TCP-порт 22 перед активацией UFW. Это достигается с помощью следующей команды.
sudo ufw разрешить 22 / tcp
или
sudo ufw разрешить ssh
Возможно, вы захотите разрешить трафик HTTP и HTTPS, поэтому выполните следующую команду, чтобы разрешить входящее соединение на TCP-портах 80 и 443.
sudo ufw позволяет 80 / tcp sudo ufw разрешить 443 / tcp
Если вы используете почтовый сервер, вам необходимо разрешить TCP-порт 25 (SMTP), 587 (отправка), 143 (imap) и 993 (imaps).
sudo ufw позволяет 25 / tcp sudo ufw разрешить 587 / tcp sudo ufw разрешить 143 / tcp sudo ufw разрешить 993 / tcp
Если вы хотите, чтобы ваш пользователь мог использовать протокол POP3, вам необходимо разрешить TCP-порт 110 (POP3) и 995 (POP3S).
sudo ufw разрешить 110 / tcp sudo ufw разрешить 995 / tcp
Если вы запускаете DNS-сервер BIND, вам необходимо открыть 53 порт TCP и UDP.
sudo ufw разрешить 53
Приведенная выше команда разрешит порт TCP и UDP.Если вы хотите разрешить только порт UDP, тогда
sudo ufw разрешить 53 / udp
Открытие нескольких портов одновременно
Вы можете разрешить несколько портов, как показано ниже.
sudo ufw разрешить 80,443,25,587,465,143,993 / tcp
Включение UFW
После того, как вы установили разрешенные порты в UFW, вам необходимо включить UFW. Но перед этим рекомендуется включить ведение журнала с помощью следующей команды, чтобы вы могли лучше понять, правильно ли работает ваш брандмауэр.
sudo ufw вход в систему
Уровень журнала по умолчанию - «низкий». Файл журнала: /var/log/ufw.log . Я обычно использую «средний» уровень журнала.
sudo ufw средство ведения журнала
Теперь включите UFW.
sudo ufw включить
Примечание. Если вы ранее использовали брандмауэр iptables напрямую, эти правила брандмауэра iptables будут отменены после включения UFW.
Проверить статус
sudo ufw статус
Чтобы получить дополнительную информацию, запустите
.sudo ufw статус подробный
Теперь вы можете повторно просканировать свой сервер, чтобы узнать, какие порты все еще открыты.
судо nmap 12.34.56.78
Также включите службу UFW systemd, чтобы она автоматически запускалась при загрузке системы.
sudo systemctl включить ufw
Как удалить правило брандмауэра
Во-первых, вам нужно получить ссылочный номер правила брандмауэра, которое вы хотите удалить, с помощью следующей команды.
sudo ufw статус с номером
Затем вы можете удалить правило, например 8-е правило.
sudo ufw удалить 8
Обратите внимание, что ссылочный номер изменится после удаления правила, поэтому вам нужно снова запустить команду sudo ufw status с номером , чтобы удалить другое правило.
Сброс UFW
Если вы допустили ошибку, вы можете отключить брандмауэр и восстановить настройки по умолчанию.
sudo ufw сброс
Это особенно полезно для новичков.
Профиль приложения UFW
Многие серверные программы поставляются с профилями UFW. Вы можете перечислить все профили приложений с помощью:
список приложений sudo ufw
Мы можем отображать информацию о конкретном профиле приложения, например, о профиле «Apache Full».
информация о приложении sudo ufw "Apache Full"
Мы видим, что порт, используемый этим профилем, - это TCP-порт 80 и 443. Если мы активируем этот профиль приложения с помощью следующей команды, TCP-порты 80 и 443 будут разрешены.
sudo ufw разрешить "Apache Full"
Создание черного списка IP-адресов с помощью UFW
Допустим, спамер постоянно пытается отправить спам на ваш почтовый сервер. Вы можете использовать UFW, чтобы заблокировать IP-адрес спамера от доступа к TCP-порту 25 вашего почтового сервера, с помощью следующей команды.Замените 12.34.56.78 на IP-адрес спамера.
sudo ufw insert 1 deny in с 12.34.56.78 на любой порт 25 proto tcp
Обратите внимание, что вновь добавленные правила брандмауэра по умолчанию помещаются внизу. Если вы ранее разрешили доступ к порту 25 из любого места, вам нужно вставить правило запрета в качестве первого правила, как указано выше, поэтому правило запрета будет применено первым. Вы всегда можете вставить новое правило запрета в качестве первого правила.
sudo ufw insert 1 deny in from 78.56.34.12 на любой порт 25 proto tcp
Вы также можете заблокировать диапазон IP-адресов, как показано ниже.
sudo ufw insert 1 deny in from 192.168.0.0/24 на любой порт 25 proto tcp
Чтобы заблокировать IP-адрес от доступа ко всем портам на вашем сервере, запустите
sudo ufw insert 1 deny in from 12.34.56.78
Создание белого списка IP-адресов с помощью UFW
Теперь предположим, что вы запускаете сервер OpenSSH и хотите разрешить вход на ваш сервер только определенному IP-адресу через SSH.Вы можете использовать UFW для создания белого списка IP-адресов. Например, у меня дома нет статического IP-адреса, но я настроил несколько VPN-серверов в облаке, поэтому теперь я могу настроить UFW, чтобы разрешить входящее подключение к порту 22 только с IP-адреса моего VPN-сервера.
Сначала добавьте IP-адрес в список разрешенных.
sudo ufw insert 1 разрешить с 12.34.56.78 на любой порт 22 proto tcp
Затем вам нужно получить ссылочный номер правила разрешения SSH из любого места и удалить это правило.
sudo ufw статус пронумерован sudo ufw удалить ссылочный номер
Обратите внимание, что вам необходимо удалить как правило IPv4, так и правило IPv6. Также обратите внимание, что если вы сначала удалите верхнее правило, ссылочный номер нижнего правила изменится.
С этого момента только ваш IP-адрес может получить доступ к TCP-порту 22.
Как использовать IPv6-адрес в UFW
Сначала убедитесь, что IPV6 = yes установлен в файле / etc / default / ufw .Если он не установлен, добавьте его в этот файл и перезапустите UFW (sudo systemctl restart ufw).
Затем вы можете просто заменить IPv4 на IPv6-адрес в командах ufw, как показано ниже.
sudo ufw разрешить с 2607: f8b0: 4005: 804 :: 200e на любой порт 587
Обратите внимание, что вы не можете вставить правило IPv6 между правилами IPv4. Правила IPv6 всегда следует размещать после правил IPv4.
Как настроить IP-маскарадинг с помощью UFW
Иногда вы хотите настроить свой собственный VPN-сервер, тогда вам нужно будет настроить IP-маскировку на своем VPN-сервере, чтобы он стал виртуальным маршрутизатором для VPN-клиентов.К сожалению, UFW не предоставляет удобного способа сделать это. Мы должны добавить команду iptables в файл конфигурации UFW.
судо нано /etc/ufw/before.rules
По умолчанию для таблицы filter есть несколько правил. Добавьте следующие строки в конец этого файла.
# Правила таблицы NAT * нац : ПРИНЯТИЕ ПОСТРОУТИРОВКИ [0: 0] # Перенаправлять трафик через eth0 - Измените eth0 в соответствии с вашим сетевым интерфейсом -A ПОСТРОУТИРОВАНИЕ -o eth0 -j МАСКАРАД # Заканчивайте каждую таблицу строчкой COMMIT, иначе эти правила не будут обработаны СОВЕРШИТЬ
Обратите внимание, что если ваш основной сетевой интерфейс не eth0 , вам нужно изменить eth0 на имя вашего сетевого интерфейса, которое можно получить с помощью команды ip addr .И поскольку мы добавляем правила брандмауэра в новую таблицу, а именно в таблицу nat , нам нужно добавить строку «COMMIT».
По умолчанию UFW запрещает пересылку пакетов, что хорошо, потому что не позволяет случайным людям в Интернете использовать ваш ящик для злонамеренных действий. Но нам нужно разрешить пересылку для нашей частной сети. Найдите в этом файле цепочку ufw-before-forward и добавьте следующие 3 строки, которые будут принимать пересылку пакетов, если IP-адрес источника или IP-адрес назначения находится в 10.10.10.0 / 24 диапазон.
# разрешить пересылку для доверенной сети -A ufw-before-forward -s 10.10.10.0/24 -j ПРИНЯТЬ -A ufw-before-forward -d 10.10.10.0/24 -j ПРИНЯТЬ
Сохраните и закройте файл. Затем перезапустите UFW.
sudo ufw отключить sudo ufw enable
или просто
sudo systemctl перезапуск ufw
Хотя это не связано с конфигурацией UFW, но для маршрутизации пакетов вам также необходимо настроить переадресацию IP.Это можно сделать, установив следующее в конце файла /etc/sysctl.conf .
net.ipv4.ip_forward = 1
Затем примените изменения с помощью следующей команды.
судо sysctl -p
Как настроить переадресацию портов в UFW
Что делать, если вы используете UFW на своем маршрутизаторе и хотите маршрутизировать пакеты, такие как HTTP-запросы, на внутренние узлы LAN? В этом случае вам необходимо настроить переадресацию портов. Отредактируйте файл /etc/ufw/before.rules .
судо нано /etc/ufw/before.rules
Затем добавьте следующие строки в таблицу NAT над строкой COMMIT. Замените 12.34.56.78 общедоступным IP-адресом вашего маршрутизатора.
: ПРИНЯТИЕ ПЕРЕДАЧИ [0: 0] # переслать 12.34.56.78 порт 80 на 192.168.1.100:80 # переадресовать 12.34.56.78 порт 443 на 192.168.1.100:443 -A PREROUTING -i eth0 -d 12.34.56.78 -p tcp --dport 80 -j DNAT --to-destination 192.168.1.100:80 -A PREROUTING -i eth0 -d 12.34.56.78 -p tcp --dport 443 -j DNAT --to-destination 192.168.1.100: 443
Это указывает UFW использовать цель DNAT для пересылки запросов HTTP и HTTPS на хост 192.168.100 в локальной сети.
Подсказка : DNAT (Destination NAT) изменяет IP-адрес назначения. Типичный пример - переадресация портов. SNAT (Source NAT) изменяет исходный IP-адрес. Типичный пример - когда хост за маршрутизатором Wi-Fi хочет просматривать Интернет.
Очистить правила таблицы NAT.
судо iptables -F -t нат
Перезапустите UFW для обработки всех правил NAT.
sudo systemctl перезапуск ufw
Также необходимо включить переадресацию IP в файле /etc/sysctl.conf , как указано выше.
Если на хосте 192.168.1.100 также работает UFW, вам необходимо разрешить порты 80 и 443 в UFW.
sudo ufw позволяет 80 / tcp sudo ufw разрешить 443 / tcp
Обратите внимание, что хост 192.168.1.100 LAN должен использовать маршрутизатор UFW в качестве шлюза. Если в качестве шлюза используется другой IP-адрес, переадресация портов работать не будет.
Как заблокировать BitTorrent-трафик на облачных серверах
Если вы запускаете сервер в облаке, вы, вероятно, захотите заблокировать BitTorrent-трафик на сервере, потому что, если вы или кто-то другой случайно загрузите нелегальный контент (фильмы, телешоу) через BitTorrent и вас поймают, ваш хостинг-провайдер, скорее всего, приостановит работу. ваш счет.
Современные клиенты BitTorrent шифруют трафик между одноранговыми узлами, поэтому отличить трафик BitTorrent от других типов трафика непросто. Хотя нет идеального способа заблокировать BitTorrent-трафик, вот простое решение.
По умолчанию блокировать исходящий трафик.
sudo ufw default запретить исходящий
Затем разрешите определенные исходящие порты. Например, вам нужно разрешить порт DNS.
sudo ufw разрешить 53
И вам необходимо разрешить портам 80 и 443 обновлять ваши программные пакеты из репозитория.
sudo ufw разрешить 80 / tcp sudo ufw разрешить 443 / tcp
Если это ваш почтовый сервер, вам необходимо разрешить порт 25.
sudo ufw разрешить 25 / tcp
Перезапустите UFW, чтобы изменения вступили в силу.
sudo systemctl перезапуск ufw
Хотя это не идеальное решение, поскольку некоторые пользователи могут настроить свои BitTorrent-клиенты на использование порта 80 или 443, в действительности такая ситуация встречается довольно редко. Большинство пользователей просто используют настройки по умолчанию, и мой BitTorrent-клиент на сервере немедленно прекращает все загрузки и выгрузки, когда я применяю вышеуказанные правила в брандмауэре.Если это не прекратится, перезапустите клиент BitTorrent или сервер.
Блокировка исходящих подключений к определенному IP-адресу
Во-первых, нужно разрешить исходящий трафик.
sudo ufw по умолчанию разрешить исходящие
Затем заблокируйте определенный IP-адрес с помощью:
sudo ufw insert 1 deny out to 12.34.56.78
Перезапустите UFW.
sudo systemctl перезапуск ufw
UFW и fail2ban
Fail2ban - это программа, которая использует брандмауэр iptables для защиты серверов от атак грубой силы.UFW и Fail2ban не будут мешать друг другу.
Вот и все! Надеюсь, эта статья помогла вам использовать UFW в Debian, Ubuntu и Linux Mint. Как всегда, если вы нашли этот пост полезным, подпишитесь на нашу бесплатную рассылку, чтобы получать больше советов и рекомендаций. Береги себя 🙂
.