| Diffuse reflective | Threaded | M6 | 6 mm | -40-70 °C | 2 m | Головка оптоволоконного датчика диффузного типа, M6 головка, большая дистанция, стандартное оптоволокно, мин. радиус изгиба R25, кабель 2м | ||||||
| Diffuse reflective | Threaded | M4 | 2.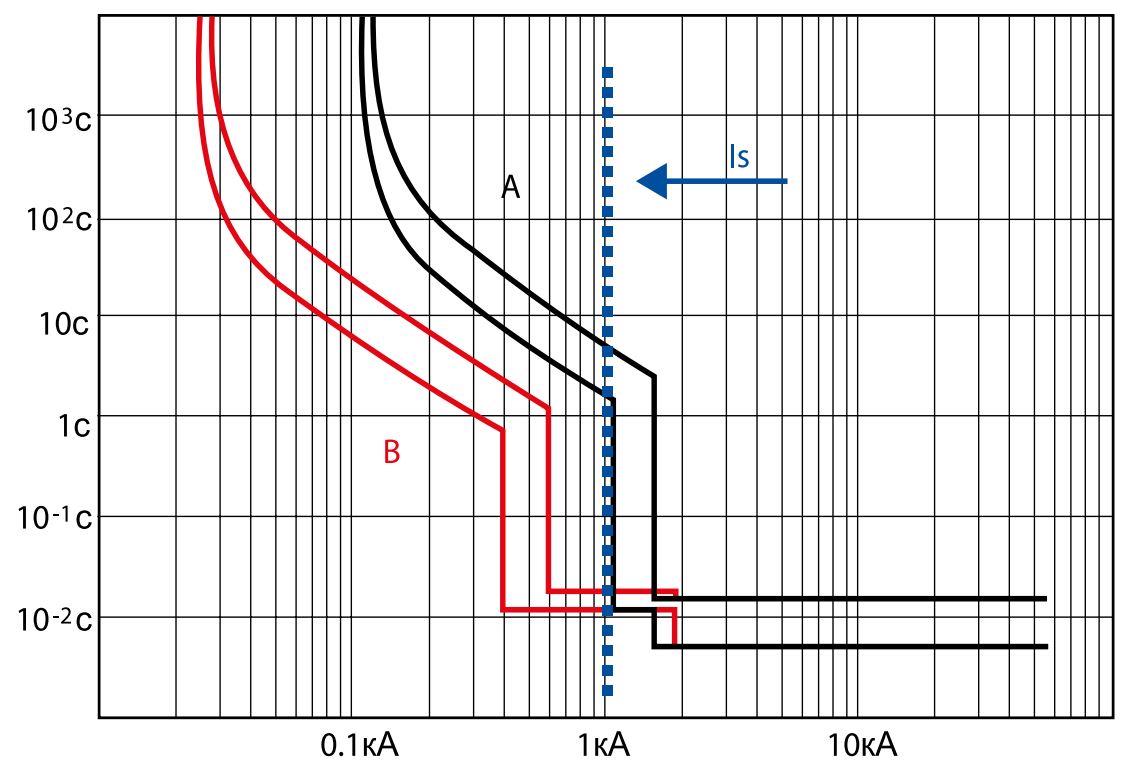 5 mm 5 mm | -40-70 °C | 390 mm | 2 m | Головка оптоволоконного датчика диффузного типа, M4 головка, большая дистанция, дист. до 210 мм, стандартное оптоволокно с мин. радиусом изгиба R10 кабель 2м | |||||
| Diffuse reflective | Cylindrical axial | 3 mm | -40-70 °C | 2 m | Головка оптоволоконного датчика диффузного типа, 3мм диаметр головки, большая дистанция, стандартное оптоволокно с мин. радиусом изгиба R10, кабель 2м радиусом изгиба R10, кабель 2м | |||||||
| Diffuse reflective | M6 | 1.5 mm | -40-70 °C | 540 mm | 2 m | Оптоволокно, диффузное, коаксиальное, головка M6, с линзами увелич. расстояния, стандартной гибкости, мин. радиус изгиба R25, длина 2м | ||||||
| Diffuse reflective | Threaded | M6 | 6 mm | 90° cable exit, Flexible fiber, Hexagonal back | -40-70 °C | 520 mm | 2 m | Fiber optic sensor, diffuse, M6 hex right-angled head, integrated lens, high-flex R2 fiber, 2m cable | ||||
| Diffuse reflective | Threaded | M6 | 1. 5 mm 5 mm | -40-70 °C | 520 mm | 2 m | Fiber optic sensor, diffuse, M6 head, long distance, high flex R1 fiber, 2 m cable | |||||
| Through-beam | Threaded | M4 | 4 mm | -40-70 °C | 4000 mm | 2 m | Головка оптоволоконного датчика на пересечение луча, головка M4, увеличенное расстояние, мин. радиус изгиба 25мм, кабель 2м радиус изгиба 25мм, кабель 2м | |||||
| Through-beam | Threaded | M4 | 4 mm | 90° cable exit, Flexible fiber, Hexagonal back | -40-70 °C | 4000 mm | 2 m | Fiber optic sensor, through-beam, M4 hex right-angled head, integrated lens, high-flex R2 fiber, 2 m cable | ||||
| Through-beam | Threaded | M4 | 4 mm | Flexible fiber, R1 Bending radius 1 mm | 4000 mm | 2 m | Fiber optic sensor, through-beam, M4 head, long distance, high flex R1 fiber, 2m cable | |||||
| Retro-reflective | Square | 27 mm | 10 mm | 21. 5 mm 5 mm | -40-70 °C | 2250 mm | 2 m | Оптоволокно, рефлекторное, для больших дистанций, R25, длина 2м (укорачиваемое) | ||||
| Threaded | M4 | 4 mm | -40-70 °C | 3900 mm | 2 m | Головка оптоволоконного датчика на пересечение луча, M4 головка, большая дистанция, стандартное оптоволокно, мин. радиус изгиба R25, кабель 2м радиус изгиба R25, кабель 2м | ||||||
| Through-beam | Cylindrical axial | 3 mm | -40-70 °C | 3900 mm | 2 m | Головка оптоволоконного датчика на пересечение луча, 3мм диаметр головки, большая дистанция, стандартное оптоволокно, мин. радиус изгиба R25, кабель 2м | ||||||
| Through-beam | Square | 10. 5 mm 5 mm | 8 mm | 25.2 mm | -40-70 °C | 4000 mm | 2 m | Оптоволоконо, на пересечение луча, боковая оптика, длина 2м | ||||
| Through-beam | Square | 10.5 mm | 8 mm | 25.2 mm | -40-70 °C | 4000 mm | 5 m | Головка оптоволоконного датчика на пересечение луча, с резьбовым креплением угловая головка (правая), большая дистанция до 4000мм, стандартное оптоволокно, мин. радиус изгиба R25, кабель 5м радиус изгиба R25, кабель 5м | ||||
| Through-beam | Threaded | M3 | 3 mm | -40-70 °C | 1200 mm | 2 m | Головка оптоволоконного датчика на пересечение луча, M3 головка, большая дистанция, стандартное оптоволокно с мин. радиусом изгиба R10, кабель 2м | |||||
| Through-beam | Cylindrical axial | dia 2 mm | 2 mm | -40-70 °C | 1200 mm | 2 m | Головка оптоволоконного датчика на пересечение луча, 2мм диаметр головки, большая дистанция, стандартное оптоволокно с мин. радиусом изгиба R10, кабель 2м радиусом изгиба R10, кабель 2м | |||||
| Through-beam | Threaded | M3 | 3 mm | -40-70 °C | 2000 mm | 2 m | Головка оптоволоконного датчика на пересечение луча, M3 головка, до 900 мм, стандартное оптоволокно, мин. радиус изгиба R25, кабель 2м |
Ложные срабатывания: почему с ними надо бороться и как мы добились лучших показателей
В погоне за высоким уровнем обнаружения киберугроз, в индустрии информационной безопасности тема ложных срабатываний часто оказывается незаслуженно забытой. Действительно, это очень неудобная тема, которую некоторые разработчики стараются не замечать (или решать сомнительными способами) – до первого серьёзного инцидента, способного парализовать работу клиентов. К сожалению такие инциденты действительно случаются. И к сожалению, только потом приходит понимание, что качественная защита от киберугроз – это не только предотвращение (prevention), но и низкий уровень ложных срабатываний.
Действительно, это очень неудобная тема, которую некоторые разработчики стараются не замечать (или решать сомнительными способами) – до первого серьёзного инцидента, способного парализовать работу клиентов. К сожалению такие инциденты действительно случаются. И к сожалению, только потом приходит понимание, что качественная защита от киберугроз – это не только предотвращение (prevention), но и низкий уровень ложных срабатываний.
При кажущейся простоте темы минимизации ложных срабатываний, в ней, на самом деле, много сложностей и подводных камней, которые требуют от разработчиков значительных инвестиций, технологической зрелости и ресурсов.
Две основные причины появления ложных срабатываний — (i) программные, аппаратные и человеческие ошибки на стороне разработчика, (ii) многообразие легального («чистого») программного обеспечения, которое проходит проверку системой безопасности. Последняя причина требует пояснения. Действительно, программы пишут миллионы человек разной квалификации (от студента до профессионала) по всему миру, пользуясь разными платформами и стандартами. У каждого автора свой неповторимый стиль, при этом «почерк» программного кода действительно иногда напоминает вредоносный файл, на что и срабатывают защитные технологии, в особенности, основанные на поведенческом анализе и машинном обучении.
У каждого автора свой неповторимый стиль, при этом «почерк» программного кода действительно иногда напоминает вредоносный файл, на что и срабатывают защитные технологии, в особенности, основанные на поведенческом анализе и машинном обучении.
Без учёта этой специфики и без внедрения специальных технологий для минимизации ложных срабатываний разработчики рискуют проигнорировать принцип «не навреди». А это, в свою очередь, приводит к чудовищным последствиям (особенно для корпоративных заказчиков), сопоставимым с потерями от самих вредоносных программ.
Лаборатория Касперского более двадцати лет развивает процессы разработки и тестирования, а также создаёт технологии для минимизации ложных срабатываний и сбоев у пользователей. Мы гордимся одним из лучших в индустрии результатов по этому показателю (тесты AV-Comparatives, AV-Test.org, SE Labs) и готовы подробнее рассказать о некоторых особенностях нашей «внутренней кухни». Уверен, что эта информация позволит пользователям и корпоративным заказчикам делать более обоснованный выбор системы безопасности, а разработчикам программного обеспечения – усовершенствовать свои процессы в соответствии с лучшими мировыми практиками.
Мы используем трёхуровневую систему контроля качества для минимизации ложных срабатываний: (i) контроль на уровне дизайна, (ii) контроль при выпуске метода детекта и (iii) контроль выпущенных детектов. При этом система постоянно улучшается за счёт разного рода профилактических мер.
Давайте более подробно рассмотрим каждый уровень системы.
Контроль на уровне дизайна
Один из наших главных принципов в разработке – каждая технология, продукт или процесс априорно должны содержать механизмы для минимизации рисков ложных срабатываний и сопутствующих сбоев. Как известно, ошибки на уровне дизайна оказываются самыми дорогостоящими, ведь для их полноценного исправления может потребоваться переделка всего алгоритма. Поэтому с годами мы выработали собственные лучшие практики, позволяющие уменьшить вероятность неправильного срабатывания.
Например, при разработке или улучшении технологии детектирования киберугроз на основе машинного обучения, мы убеждаемся, что обучение технологии происходило на значительных коллекциях чистых файлов разных форматов. Помогает в этом наша база знаний о чистых файлах (списки разрешенных), которая уже превысила 2 миллиарда объектов и постоянно пополняется в сотрудничестве с производителями программного обеспечения.
Помогает в этом наша база знаний о чистых файлах (списки разрешенных), которая уже превысила 2 миллиарда объектов и постоянно пополняется в сотрудничестве с производителями программного обеспечения.
Также мы убеждаемся, что в процессе работы обучающие и тестовые коллекции каждой технологии постоянно обновляются актуальными чистыми файлами. В продукты встроены механизмы для минимизации ложных срабатываний на критических для операционной системы файлах. Помимо этого, при каждом детектировании продукт посредством Kaspersky Security Network (KSN) обращается к базе данных вайтлистинга и сервису репутации сертификатов, чтобы убедиться – это не чистый файл.
Впрочем, помимо технологий и продуктов есть пресловутый человеческий фактор.
Вирусный аналитик, разработчик экспертной системы, специалист по анализу данных могут ошибиться на любой стадии, так что и здесь есть место для разнообразных блокирующих проверок, а также подсказок/предупреждений/запретов в случае опасных действий, обнаруживаемых автоматическими системами.
Контроль при выпуске метода детекта
Перед доставкой пользователям новые методы обнаружения киберугроз проходят ещё несколько стадий тестирования.
Важнейший защитный барьер – инфраструктурная система тестирования на ложные срабатывания, работающая с двумя коллекциями.
Первая коллекция (critical set) состоит из файлов популярных операционных систем разных платформ и локализаций, обновлений этих операционных систем, офисных приложений, драйверов и наших собственных продуктов. Это множество файлов регулярно пополняется.
Вторая коллекция содержит динамически формируемый набор файлов, составленный из наиболее популярных на текущий момент файлов. Размер этой коллекции выбран таким образом, чтобы найти баланс между объёмом сканируемых файлов (как следствие, количеством серверов), временем такого сканирования (а значит, временем доставки методов детекта пользователям) и максимальным потенциальным ущербом в случае ложного срабатывания.
Сейчас размер обеих коллекций превышает 120 миллионов файлов (около 50Tb данных). Учитывая, что они сканируются каждый час при каждом выпуске обновлений баз, то можно сказать, что инфраструктура за сутки проверяет более 1,2Pb данных на ложные срабатывания.
Учитывая, что они сканируются каждый час при каждом выпуске обновлений баз, то можно сказать, что инфраструктура за сутки проверяет более 1,2Pb данных на ложные срабатывания.
Более 10 лет назад мы одними из первых в индустрии информационной безопасности начали внедрять несигнатурные методы детектирования, основанные на поведенческим анализе, машинном обучении и других перспективных обобщающих технологиях. Эти методы показали свою эффективность, в особенности для борьбы со сложными киберугрозами, однако требуют особо тщательного тестирования на ложные срабатывания.
Например, поведенческое детектирование позволяет заблокировать вредоносную программу, проявившую во время работы элементы вредоносного поведения. Чтобы не допустить ложного срабатывания на поведение чистого файла, мы создали «ферму» из компьютеров, реализующих многообразные пользовательские сценарии.
На «ферме» представлены различные комбинации операционных систем и популярного программного обеспечения. Перед выпуском новых несигнатурных методов детектирования они проверяются в динамике на этой «ферме» в типовых и специальных сценариях.
Перед выпуском новых несигнатурных методов детектирования они проверяются в динамике на этой «ферме» в типовых и специальных сценариях.
Наконец, нельзя не упомянуть про необходимость проверки на ложные срабатывания для сканера веб-контента. Ошибочное блокирование вебсайта также может повлечь за собой перебои в работе на стороне заказчика, что в нашей работе неприемлемо.
Для минимизации этих инцидентов автоматизированные системы ежедневно выкачивают актуальный контент 10 тысяч самых популярных сайтов Интернета и сканируют их содержимое нашими технологиями для проверки на ложные срабатывания. Для достижения наиболее точных результатов контент скачивается реальными браузерами наиболее распространённых версий, а также используются прокси, чтобы исключить предоставление геозависимого контента.
Контроль выпущенных детектов
Доставленные пользователям методы детектирования находятся под круглосуточным наблюдением автоматических систем, отслеживающих аномалии в поведении этих детектов.
Дело в том, что динамика детекта, вызывающего ложное срабатывание нередко отличается от динамики детекта действительно вредоносных файлов. Автоматика отслеживает такие аномалии и при возникновении подозрений просит аналитика произвести дополнительную проверку сомнительного детекта. А при уверенных подозрениях автоматика самостоятельно отключает этот детект через KSN, при этом срочно информируя об этом аналитиков. Кроме того, три команды дежурных вирусных аналитиков в Сиэтле, Пекине и Москве посменно и круглосуточно наблюдают за обстановкой и оперативно решают возникающие инциденты. Humachine Intelligence в действии.
Помимо аномальных детектов, умные автоматические системы отслеживают показатели производительности, ошибки в работе модулей и потенциальные проблемы на основе диагностических данных, присылаемых от пользователей через KSN. Это позволяет нам на ранних этапах обнаруживать потенциальные проблемы и устранять их, пока их влияние не стало заметно для пользователей.
В случае, если инцидент все-таки случился и его нельзя закрыть отключением отдельного метода детектирования, то для исправления ситуации применяются срочные меры, которые позволяют быстро и эффективно решить проблему. В этом случае мы можем моментально «откатить» базы к стабильному состоянию, причём для этого не требуется дополнительного тестирования. Сказать по правде, мы ещё ни разу не воспользовались таким методом на практике — не было повода. Только на учениях.
В этом случае мы можем моментально «откатить» базы к стабильному состоянию, причём для этого не требуется дополнительного тестирования. Сказать по правде, мы ещё ни разу не воспользовались таким методом на практике — не было повода. Только на учениях.
Кстати, про учения.
Профилактика лучше лечения
Не всё можно предусмотреть, а даже предусмотрев всё, хорошо бы узнать, как все эти меры сработают на практике. Для этого не обязательно ждать реального инцидента – его можно смоделировать.
Для проверки боеготовности персонала и эффективности методов предотвращения ложных срабатываний мы регулярно проводим внутренние учения. Учения сводятся к полноценной имитации различных «боевых» сценариев с целью проверить, что все системы и эксперты действуют по плану. Учения вовлекают сразу несколько подразделений технического и сервисного департаментов, назначается на выходной день и проводится на основе тщательно продуманного сценария. После учения проводится анализ работы каждого подразделения, улучшается документация, вносятся изменения в системы и процессы.
Иногда в процессе учения можно выявить новый риск, который ранее не замечали. Более системно выявлять такие риски позволяют регулярные мозговые штурмы потенциальных проблем в области технологий, процессов и продуктов. Ведь технологии, процессы и продукты постоянно развиваются, а любое изменение несёт новые риски.
Наконец, по всем инцидентам, рискам и проблемам, вскрытым учениями, ведётся системная работа над устранением корневых причин.
Излишне говорить, что все системы, отвечающие за контроль качества, продублированы и поддерживаются круглосуточно командой дежурных администраторов. Сбой одного звена приводит к переходу на дублирующее и оперативное исправление самого сбоя.
Заключение
Совсем избежать ложных срабатываний невозможно, но можно сильно снизить вероятность их возникновения и минимизировать последствия. Да, это требует от разработчика значительных инвестиций, технологической зрелости и ресурсов. Но эти усилия обеспечивают бесперебойную работу пользователей и корпоративных заказчиков. Такие усилия необходимы, это часть обязанностей каждого надёжного поставщика систем кибербезопасности.
Надёжность – наше кредо. Вместо того, чтобы полагаться на какую-то одну технологию защиты, мы используем многоуровневую систему безопасности. Похожим образом устроена и защита от ложных срабатываний – она также многоуровневая и многократно продублирована. По-другому нельзя, ведь речь идёт о качественной защите инфраструктуры заказчиков.
При этом, нам удаётся найти и поддерживать оптимальный баланс между самым высоким уровнем защиты от киберугроз и очень низким уровнем ложных срабатываний. Об этом свидетельствуют результаты независимых тестов: по итогам 2016 г. Kaspersky Endpoint Security получил от немецкой тестовой лаборатории AV-Test.org сразу восемь наград, в том числе «Best Protection» и «Best Usability».
В заключении отмечу, что качество – это не однократно достигнутый результат. Это процесс, требующий постоянного контроля и совершенствования, особенно в условиях, когда цена возможной ошибки – нарушение бизнес-процессов заказчика.
Ложные срабатывания. Новая техника ловли двух зайцев / Хабр
Проблема ложных срабатываний. Точность и полнота.
Если есть универсальная болевая точка DLP-систем, то это, без сомнения, ложные срабатывания. Они могут быть вызваны неправильной настройкой политик, но соль в том, что даже если интегратор постарался, и все внедрено-настроено грамотно, ложные срабатывания все равно никуда не исчезают. И их много. Если услышите, что у кого-то их нет, не верьте, “everybody lies”. Мы долго в этой отрасли, и все серьезные конкурентные решения регулярно тестируем. Ложные срабатывания – это бич всех современных DLP, от которого страдают прежде всего заказчики.
В этой статье мы расскажем о новом подходе к политикам фильтрации информационного трафика на предмет риска ИБ. Метод основан на применении двух этапов фильтрации, что отличает его от традиционной одноуровневой фильтрации. Такой подход позволяет более эффективно решать проблему ложных срабатываний, т.е. сокращать и мусор, и долю пропущенных инцидентов.
Сегодня будет немного теории, а через неделю — много практики.
Прежде всего, напомним 2 свойства, определяющих качество любого механизма фильтрации информации, а именно: точность и полнота (precision and recall, на языке статистики — ошибки I-го и II-го рода).
Представим себе некую компанию с информационным трафиком. В нем имеется некая выборка документов, состоящая из множества A – ценных документов. Фильтрационный механизм должен выявить их в информационном трафике. Точность — это доля документов, верно отмеченных как ценные среди всех отмеченных фильтром, а полнота — доля верно найденных из заранее известного множества ценных документов А. Попробуем расписать это в виде формул, чтобы было чуть понятнее.
Например, А = 10 коммерческих предложений. Наш фильтр нашел B = 8 документов верно и C = 4 ложно, следовательно, D = 2 документа мы не нашли. Тогда:
Естественно, что точность и полнота противостоят друг другу. Проиллюстрируем это на простом примере условия фильтрации.
В качестве условий детектирования информации на предмет риска ИБ выступают ключевые слова, количество вложений, число получателей, форматы файлов, тональность лексики и еще миллион условий. Без потери общности мы выберем в качестве такого условия размер файла V.
Пусть для некоторой организации распределение количества файлов ценной информации и мусора по размеру файла выглядит следующим образом:
Тогда борьба за точность даст такой результат поиска (найдены файлы размером > V ):
Естественно, такая политика фильтрации не годится по самой банальной причине — мы теряем из вида львиную долю важной информации, что недопустимо. Однако одновременно эта политика дает нам и серьезное преимущество. Известно, что инциденты ИБ высокой критичности подвергаются незамедлительному разбору, и такой подход, при котором мы сразу получаем наиболее критичные инциденты без лишнего мусора, позволяет повысить скорость реагирования.
Борьба за полноту будет выглядеть так (найдены файлы размером > V ):
В этой ситуации, более привычной и характерной для отечественных реалий, политика информационной безопасности размечает значительно больше трафика, сохраняя при этом почти все инциденты. Но и в этом случае результат не позволяет назвать такой подход эффективным. Причина этого — снова фактор времени. Офицер безопасности сталкивается с большим числом ложных срабатываний, что замедляет реагирование на инциденты высокой критичности.
Добиться 100% точности и 100% полноты ввиду, вообще говоря, случайного характера анализируемых данных, удается редко. На чем же построены маркетинговые заявления вендоров о едва ли не отрицательном числе ложных срабатываний в их продуктах? Иногда разработчики DLP намеренно вуалируют один из показателей, выдавая его за качество детектирования, и тем самым делают арифметику невольной слугой необъективной подачи информации.
Одновременно высокие точность и полнота, как правило, встречаются в точных науках (физика, химия, биология). Например, по единственному состоянию цепочки белков можно определить уникальную (если у человека нет близнеца или клона) цепочку ДНК и её носителя. По уникальному отпечатку пальцев можно идентифицировать преступника, а по уникальному спектру поглощения можно определить химический состав вещества. В детектировании информации тоже имеется место для подобных решений. Речь идет о поиске информации по уникальному признаку (сумма MD5, или ее родственник — цифровой отпечаток). Во всех вышеперечисленных ситуациях мы имеем «свойство», однозначно отделяющее нужный объект от «мусора».
Однако по понятным причинам эта технология эффективна лишь для защиты неизменяемых файлов, чего в реальной жизни недостаточно.
Стоит отметить, что сам процесс передачи информации не является объектом изучения классических точных наук, хоть уже и имеет под собой сильный математический аппарат теории информации, заложенный Клодом Шенноном в его работах по теории связи более 70 лет назад («Теория связи в секретных системах», «Математическая теория связи»).
Нетрудно догадаться, что точность и полнота — те самые два зайца, о которых говорится в названии статьи. Во второй части мы расскажем, как же не упустить ни одного из них и решить «проклятый вопрос» всех DLP-систем — проблему ложных срабатываний.
Авторы:
Максим Бузинов, старший математик, компания Solar Security.
Галина Рябова, руководитель направления Solar Dozor, компания Solar Security.
Параметр | Описание |
Имя* | Имя уведомления. При заполнении этого поля учитывайте правила ввода данных. |
Описание | Описание уведомления. При наличии описания оно используется во всплывающей подсказке к уведомлению. Длина текста не должна превышать 10 000 символов. |
Интервал (от — до) | Период действия уведомления. По умолчанию он неограничен, то есть уведомление начинает действовать сразу же после его включения и до момента выключения или удаления. Чтобы установить определенный интервал действия, активируйте эту опцию и укажите временны́е рамки. По истечении указанного интервала уведомление автоматически выключается или, если контролируемых объектов больше нет, удаляется. |
Период контроля относительно текущего времени* | Промежуток между временем формирования сообщения и текущим временем. Если он превышен, сообщение не учитывается и уведомление не приходит. Рекомендуется указывать период контроля не менее часа, так как более короткого срока может быть недостаточно для анализа данных. |
Минимальная продолжительность тревожного состояния* | Параметр, предназначенный для того, чтобы исключить случайное срабатывание уведомления из-за погрешностей трекера (например, при ложных выездах за пределы геозоны). Укажите минимальную продолжительность тревожного состояния в секундах, минутах или часах, выбрав единицу измерения в выпадающем списке. Максимальное допустимое значение — 24 часа (1440 минут, 86400 секунд). |
Максимальное количество срабатываний | Максимальное количество срабатываний, при достижении которого уведомление автоматически отключается. Для этого параметра можно установить ограничение по времени (иконка ). В таком случае максимальное количество срабатываний применяется только к указанным интервалам, а в остальное время уведомление может срабатывать любое количество раз. При срабатывании уведомления учитывается время регистрации сообщения на сервере, а не время его формирования. Поэтому при выгрузке сообщения из черного ящика уведомление может сработать даже в том случае, если сообщение было сформировано в течение указанного интервала, а лимит срабатываний уже достигнут. |
Генерировать уведомление* | Параметр, позволяющий выбрать, когда должно срабатывать уведомление. Чтобы оно срабатывало только при изменении состояния объекта на тревожное, отметьте опцию При изменении состояния. При выборе этого варианта необходимо, чтобы в момент включения уведомления состояние объекта не было тревожным. Чтобы уведомление приходило при получении каждого тревожного сообщения, выберите опцию Для всех сообщений. |
Минимальная продолжительность предыдущего состояния* | Параметр, предназначенный для исключения излишних срабатываний. Доступен, если для параметра Генерировать уведомление выбрана опция При изменении состояния. Если до наступления тревожного состояния проходит время, равное или большее указанного в этом параметре, то срабатывает уведомление. Это позволяет избежать повторных срабатываний в тех случаях, когда тревожное состояние прерывается на небольшой промежуток времени. Укажите минимальную продолжительность предыдущего состояния в секундах, минутах или часах, выбрав единицу измерения в выпадающем списке. Максимально допустимое значение — 24 часа (1440 минут, 86400 секунд). |
Максимальное время между сообщениями* | Выпадающий список, в котором необходимо выбрать максимальное время между тревожным и предыдущим сообщениями. Доступен, если для параметра Генерировать уведомление выбрана опция При изменении состояния. Если разница во времени между тревожным и предыдущим сообщениями больше выбранной, уведомление не срабатывает. |
Таймаут* | Временной интервал после получения сообщения, по истечении которого оно должно анализироваться. Настройка доступна, если для параметра Генерировать уведомление выбрана опция При изменении состояния. Рекомендуется указывать более длительный таймаут, если в устройстве есть черный ящик, которому может потребоваться время на выгрузку всех сообщений, накопившихся в нем при потере связи (например, пока объект был за границей). Укажите таймаут в секундах или минутах, выбрав единицу измерения в выпадающем списке. Максимальное допустимое значение — 30 минут (1800 секунд). |
Включено | Состояние уведомления. Если опция активирована, то после создания уведомления оно будет включено, если нет, — выключено. |
Учитывать LBS-сообщения | Параметр, позволяющий учитывать данные о местоположении объекта, полученные при помощи базовых станций сотовой связи (LBS). |
Ограничение по времени | Настройка, позволяющая указать время и выбрать дни и/или месяцы, в которые должны контролироваться параметры уведомления. Например, они могут контролироваться только в рабочие дни и в рабочее время или только по нечетным числам и т. п. Подробнее. Если тревожное состояние началось в указанный день или интервал и его максимальная продолжительность превышена, то уведомление приходит даже в том случае, если тревожное состояние завершилось в то время, когда параметры уведомления не должны контролироваться. |
GoodTherapy | Триггер
Триггер в психологии — это стимул, такой как запах, звук или вид, который вызывает чувство травмы. Люди обычно используют этот термин при описании посттравматического стресса (ПТСР).
Что такое триггер?Триггер — это напоминание о прошлой травме. Это напоминание может вызвать у человека подавляющую грусть, беспокойство или панику. Это также может вызвать у кого-то воспоминания. Воспоминание — это яркое, часто негативное воспоминание, которое может появиться без предупреждения.Это может привести к тому, что кто-то потеряет из виду свое окружение и «заново переживет» травмирующее событие.
Триггеры могут принимать разные формы. Это может быть физическое место или годовщина травмирующего события. Человека также могут спровоцировать внутренние процессы, такие как стресс.
Иногда триггеры предсказуемы. Например, ветеран может вспоминать воспоминания во время просмотра жестокого фильма. В других случаях триггеры менее интуитивны. У человека, почувствовавшего запах ладана во время сексуального насилия, может случиться паническая атака, когда он почувствует запах того же ладана в магазине.
Некоторые люди используют термин «триггер» в контексте других проблем психического здоровья, таких как злоупотребление психоактивными веществами или беспокойство. В этих случаях триггером может быть сигнал, который вызывает усиление симптомов. Например, человека, выздоравливающего от анорексии, могут спровоцировать фотографии очень худых знаменитостей. Когда человек видит эти фотографии, он может снова почувствовать желание голодать.
Как формируются триггеры?
Точное функционирование мозга, стоящее за триггерами, до конца не изучено.Однако существует несколько теорий о том, как работают триггеры.
Когда человек находится в угрожающей ситуации, он может вступить в бой или убежать. Организм находится в состоянии повышенной готовности, уделяя первоочередное внимание всем своим ресурсам, чтобы отреагировать на ситуацию. Функции, которые не нужны для выживания, такие как пищеварение, откладываются.
Одна из функций, которой пренебрегают во время драки или бегства, — это формирование кратковременной памяти. В некоторых случаях мозг человека может неправильно записать травмирующее событие в своей памяти.Вместо того, чтобы хранить в памяти как прошлое событие, ситуация помечается как все еще существующая угроза. Когда человеку напоминают о травме, его тело действует так, как будто событие происходит, возвращаясь в режим борьбы или бегства.
В некоторых случаях сенсорный триггер может вызвать эмоциональную реакцию до того, как человек поймет, почему он расстроен. Другая теория гласит, что триггеры сильны, потому что они часто затрагивают чувства. Сенсорная информация (образы, звуки и особенно запахи) играет большую роль в памяти.Чем больше сенсорной информации хранится, тем легче вспомнить память.
Во время травматического события мозг часто закрепляет сенсорные стимулы в памяти. Даже когда человек сталкивается с теми же стимулами в другом контексте, они связывают триггеры с травмой. В некоторых случаях сенсорный триггер может вызвать эмоциональную реакцию до того, как человек поймет, почему он расстроен.
Формирование привычки также играет важную роль в инициировании. Люди склонны делать одни и те же вещи одинаково.Следование тем же образцам избавляет мозг от необходимости принимать решения.
Например, скажем, человек всегда курит за рулем. Когда человек садится в машину, его мозг ожидает, что он будет придерживаться той же процедуры и закурить сигарету. Таким образом, вождение может вызвать желание курить, даже если человек хочет бросить курить. Кого-то можно спровоцировать, даже если он не устанавливает сознательной связи между своим поведением и окружением.
Что такое триггерные предупреждения?
Триггерное предупреждение — это уведомление о потенциальных триггерах в будущем обсуждении или содержании.Цель состоит в том, чтобы позволить людям с проблемами психического здоровья избежать триггеров или подготовиться к ним. Невозможно предсказать или избежать всех триггеров, поскольку многие из них уникальны для конкретной ситуации. Предупреждения часто предназначены для общих триггеров, таких как изображения насилия.
В последнее время многие ученики запросили триггерные предупреждения в школе. Было много публичных дебатов по поводу того, подходит ли эта практика для классных комнат.
Противники триггерных предупреждений часто утверждают, что эти предупреждения предназначены для слишком чувствительных студентов.Некоторые утверждают, что предупреждения о срабатывании триггеров способствуют цензуре. Другие считают, что они ограничивают способность учителей преподавать материалы курса.
Адвокаты часто утверждают, что триггерные предупреждения необходимы для равного доступа к образованию. Триггеры могут вызывать воспоминания и панические атаки, которые мешают обучению. По данным Американской психологической ассоциации (APA), триггеры часто причиняют больше беспокойства, если становятся неожиданностью. Защитники говорят, что триггерные предупреждения позволяют студентам с посттравматическим стрессом чувствовать себя в безопасности в классе.
Если ученик говорит, что у него посттравматический стресс, уместны персонализированные триггерные предупреждения. Эффективность предупреждений о срабатывании триггеров в классе мало исследована. APA сообщает, что конкретные триггеры сложно предсказать. Таким образом, общие предупреждения о содержании класса могут быть менее эффективными. Если учащийся говорит, что у него посттравматическое стрессовое расстройство, уместны персонализированные триггерные предупреждения.
Закон об американцах с ограниченными возможностями (ADA) и Закон об инвалидах в образовании (IDEA) запрещают дискриминацию в отношении людей с ограниченными возможностями.Эти законы включают нарушения психического здоровья, такие как посттравматическое стрессовое расстройство. Федеральный закон требует от преподавателей разумного приспособления к таким лицам.
Федеральный закон конкретно не рассматривает триггерные предупреждения. Тем не менее, APA предполагает, что в некоторых случаях триггерные предупреждения могут считаться приспособлением. Преднамеренное инициирование человека с посттравматическим стрессовым расстройством может быть формой дискриминации.
Получение справки по триггерам
Предупреждения о срабатывании триггера полезны в некоторых случаях. Но избегание триггеров не решит основных проблем психического здоровья.Если триггеры мешают чьей-то повседневной жизни, человек может захотеть обратиться к терапевту.
В терапии люди могут обрабатывать эмоции, связанные с их прошлым. Некоторые могут изучить методы релаксации, чтобы справиться с паническими атаками. Другие могут научиться избегать нездорового поведения. Со временем и работой человек может столкнуться с их триггерами с гораздо меньшими страданиями.
Каталожные номера:
- ADA знайте свои права: возвращающиеся работники службы с ограниченными возможностями. (2010).Министерство юстиции США. Получено с https://www.ada.gov/servicemembers_adainfo.html .
- Поддерживает ли исследование предупреждение о срабатывании триггера в классе? (2017, 27 июля). Журналы APA Обзор статей. Получено с http://www.apa.org/pubs/highlights/spotlight/issue-97.aspx
- Приручение триггеров для улучшения психического здоровья. (2017, 31 марта). Американская психиатрическая ассоциация. Получено с https://www.psychiatry.org/news-room/apa-blogs/apa-blog/2017/03/taming-triggers-for-better-mental-health .
- Что такое триггеры посттравматического стрессового расстройства? (2017, 14 февраля).Web MD. Получено с https://www.webmd.com/mental-health/what-are-ptsd-triggers#1 .
Последнее обновление: 2 мая 2018 г.
Пожалуйста, заполните все обязательные поля, чтобы отправить свое сообщение.
Подтвердите, что вы человек.
событий, запускающих рабочие процессы — GitHub Docs
Настройка событий рабочего процесса
Вы можете настроить рабочие процессы для запуска одного или нескольких событий, используя синтаксис рабочего процесса на . Дополнительные сведения см. В разделе «Синтаксис рабочего процесса для действий GitHub».«
Пример: использование одного события
на: нажмите
Пример: использование списка событий
на: [push, pull_request]
Пример: использование нескольких событий с типами действий или конфигурацией
Если вам нужно указать типы активности или конфигурацию для события, вы должны настроить каждое событие отдельно. Вы должны добавить двоеточие (: ) ко всем событиям, включая события без конфигурации.
по:
толкать:
ветви:
- главный
pull_request:
ветви:
- главный
page_build:
выпускать:
типы:
- созданный
Для запуска рабочего процесса выполняются следующие шаги:
В вашем репозитории происходит событие, и с результирующим событием связаны SHA фиксации и Git ref.
В каталоге
.github / workflowsв вашем репозитории выполняется поиск файлов рабочего процесса в соответствующем коммите SHA или Git ref. Файлы рабочего процесса должны присутствовать в этом коммите SHA или Git ref, чтобы их можно было принять во внимание.Например, если событие произошло в определенной ветви репозитория, то файлы рабочего процесса должны присутствовать в репозитории этой ветви.
Проверяются файлы рабочего процесса для этого коммита SHA и Git ref, и запускается новый рабочий процесс для всех рабочих процессов, которые имеют значения
on:, соответствующие инициирующему событию.Рабочий процесс выполняется в коде вашего репозитория в том же коммите SHA и Git ref, которые инициировали событие. При запуске рабочего процесса GitHub устанавливает переменные среды
GITHUB_SHA(фиксация SHA) иGITHUB_REF(Git ref) в среде бегуна. Для получения дополнительной информации см. «Использование переменных среды».
Запланированные мероприятия
Расписание Событие позволяет запускать рабочий процесс в запланированное время.
Примечание. Событие расписания может быть отложено в периоды высокой загрузки рабочего процесса GitHub Actions.Время высокой загрузки включает начало каждого часа. Чтобы уменьшить вероятность задержки, запланируйте запуск рабочего процесса на другое время часа.
график